Hoy traigo otro pequeño HOWTO para recorrer una web mediante dos scripts de PHP de unas 30 líneas de código. Sí, 30 líneas, no hace falta mucho para empezar a crawlear. Hay herramientas para hacer esto, incluso algunas libres, aunque limitadas en funcionalidades. De todas formas es muy divertido hacer a modo de code-kata un robot que crawlee una web. Luego lo puedes reutilizar para un sinfin de cosas: si necesitas hacer auditorías, recopilar información, generar resultados, o re-generar más información con los contenidos crawleados.. probablemente con un simple desarrollo lo puedes resolver en poco tiempo. Quizá estás pensando en automatizar todo esto.. O quizá simplemente quieres forzar que tu web se cachee y así vaya más rápido..
Es la única forma de no estar limitado a lo que la herramienta de turno puede hacer. Si se puede pensar, se puede hacer.. pero ¡ojo! que no todo está permitido en este mundillo.
Un poco de teoría
Crawlear: es el hecho de recorrer una web obteniendo información sobre esta. Puede interesarte simplemente su estructura, si el HTML está bien formado, si tiene encabezados, utiliza secciones, etc..
Scrapear: es el hecho de guardarse la información contenida en las webs. Si luego reutilizas esta información contenida en las webs que crawleas, dependiendo de qué información reutilices y cómo lo hagas, puedes incurrir en delitos. Así que cuidadín, no te dejes llevar por el lado oscuro de la fuerza..
Una web se puede recorrer de dos formas. Repasando un poco las estructuras de datos, una web se estructura en forma de grafo dirigido, y como todo grafo dirigido, podemos recorrerlo en profundidad y en anchura. Aquí dejo dos ejemplos simplificados, para crawlear desde la HOME de una web.
La idea es recorrer la web para crear nuestro propio arbol en niveles.
Recorrido en profundidad
Es el más simple, perdemos la profundidad real de cada URL con respecto al punto de entrada (número de clicks desde el punto de entrada). El resultado final es el mismo, pero no es la mejor forma:
<?php
$theSite = $argv[1];
$visitedUrls = array($theSite => 0);
crawl_depth($visitedUrls, $theSite, $theSite, 0);
function crawl_depth(&$visitedUrls, $theSite, $currentUrl, $currentLevel)
{
echo 'FOUND:'.count($visitedUrls).' LEVEL:'.$currentLevel.' '.$currentUrl.PHP_EOL;
$dom = new DOMDocument();
@$dom->loadHTMLFile($currentUrl);
foreach ($dom->getElementsByTagName('a') as $link) {
$newUrl = $link->getAttribute('href');
// if in-site and not yet visited then follow
if (substr($newUrl, 0, strlen($theSite)) == $theSite and !array_key_exists($newUrl, $visitedUrls)) {
$visitedUrls[$newUrl] = $currentLevel + 1;
crawl_depth($visitedUrls, $theSite, $newUrl, $currentLevel + 1);
}
}
}
asort($visitedUrls);
echo '// Results ////////////////////////////////////////////'.PHP_EOL;
foreach ($visitedUrls as $key => $value) {
echo 'DEPTH:'.$value.' '.$key.PHP_EOL;
}
echo 'Total URLs found: '.count($visitedUrls).PHP_EOL;
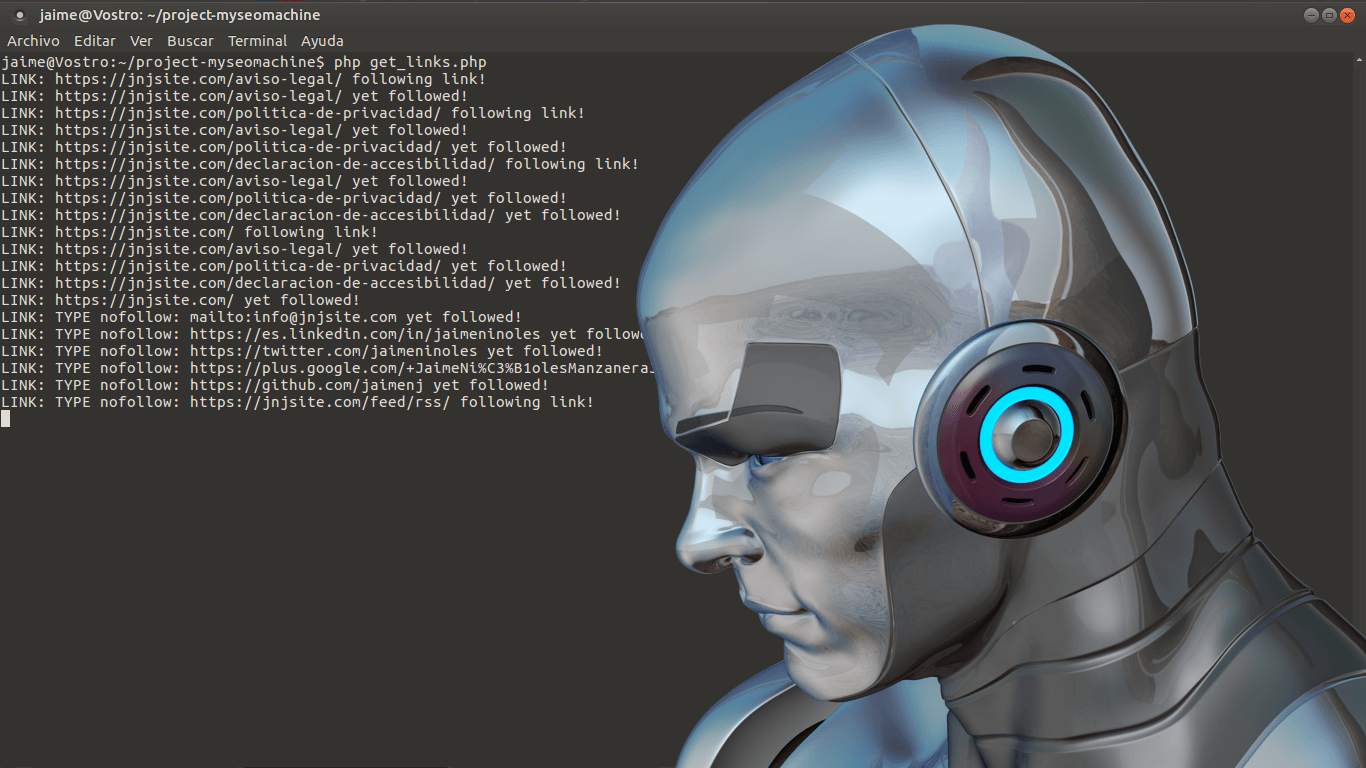
Este script lo puedes grabar en un fichero, por ejemplo llamado test.php y ejecutarlo. Mira que sólo está desarrollado para que funcione desde la HOME:
$ php test.php https://tusitioweb.com/
Debes de ver algo parecido esto:
Si nos fijamos en la imagen, el robot va navegando en profundidad por la web mientras que va añadiendo las URLs a la lista de URLs visitadas. Si vemos el nivel de cada siguiente URL va aumentando con cada visita.
Recorrido en anchura
Este es el bueno, así accedemos a la URL de entrada, recorremos todos los hijos, y después continuamos en el siguiente nivel de profundidad:
<?php
$dom = new DOMDocument();
$theSite = $argv[1];
$linksQueue = array($theSite => 0);
$visitedUrls = array(
$theSite => 0,
);
$currentLevel = 0;
while (count($linksQueue) != 0) {
$currentUrl = key($linksQueue);
$currentLevel = array_shift($linksQueue);
echo 'FOUND:'.count($visitedUrls).' QUEUE:'.count($linksQueue).' LEVEL:'.$currentLevel.' '.$currentUrl.PHP_EOL;
@$dom->loadHTMLFile($currentUrl);
foreach ($dom->getElementsByTagName('a') as $link) {
$newUrl = $link->getAttribute('href');
// if in-site and not yet visited then follow
if (substr($newUrl, 0, strlen($theSite)) == $theSite and !array_key_exists($newUrl, $visitedUrls)) {
$linksQueue[$newUrl] = $currentLevel + 1;
$visitedUrls[$newUrl] = $currentLevel + 1;
}
}
}
asort($visitedUrls);
echo '// Results ////////////////////////////////////////////'.PHP_EOL;
foreach ($visitedUrls as $key => $value) {
echo 'DEPTH:'.$value.' '.$key.PHP_EOL;
}
echo 'Total URLs found: '.count($visitedUrls).PHP_EOL;
Este recorrido se ayuda de dos colas FIFO, en la que se van encolando las URLs siguientes a visitar $linksQueue, con su profundidad, y las ya visitadas $visitedUrls. De esta forma el bucle principal se centra en recorrer las URLs que haya encoladas, y sólo añade a la cola las URLs no tenidas en cuenta todavía. Y así, según va visitando URLs las borra de una cola y las guarda en la cola de las visitadas.
Fíjate que este script no hace caso de los atributos ‘nofollow’, pero sí que comprueba que las URLs sean del mismo sitio web. Es decir, que sólo sigue los links internos.
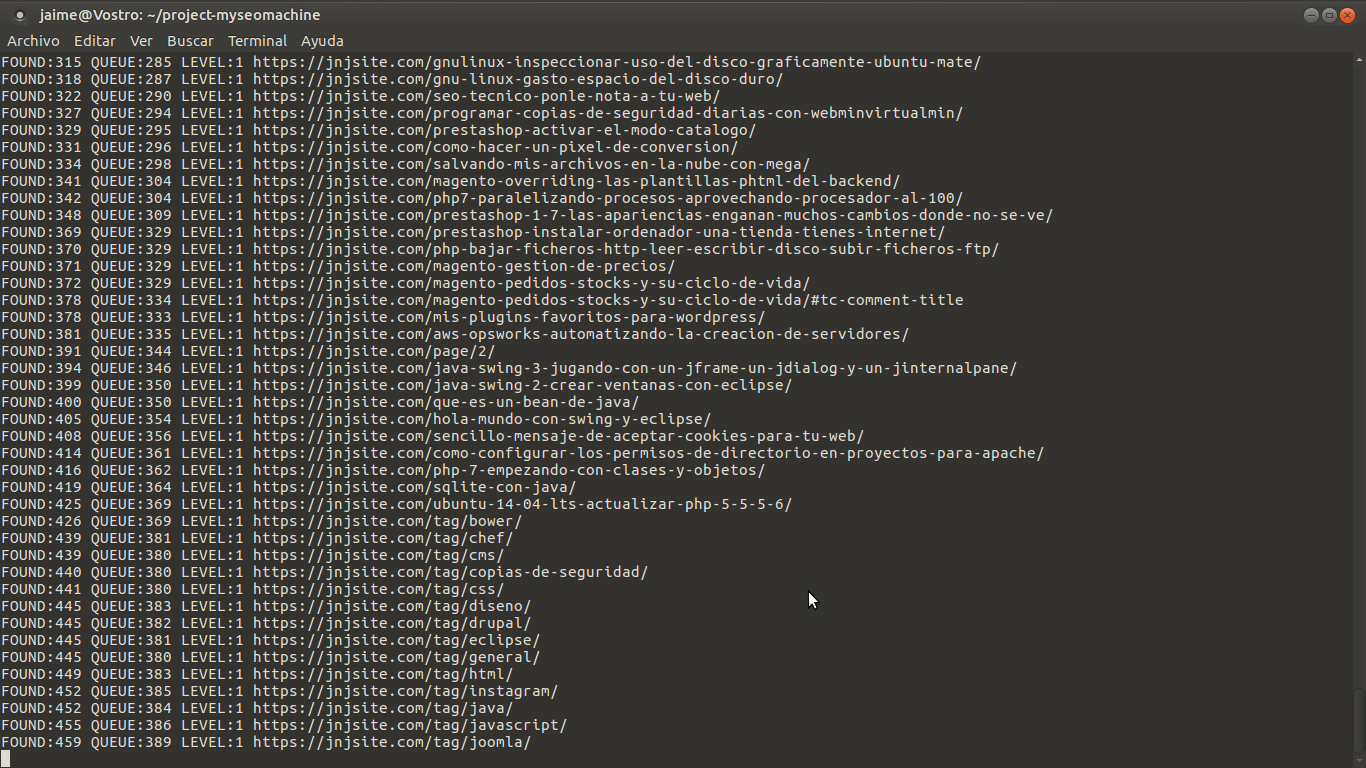
Ejecutándolo desde línea de comandos tienes que ver algo tal que asi:
Aquí lo importante es que no se sigue visitando el siguiente nivel hasta haber recorrido el nivel completo en el que estás. Este recorrido es muy importante, porque es el que realmente importa para el SEO. Nos da una idea, desde el punto de entrada, hasta donde puede llegar una visita.
Por ejemplo, si suponemos que las visitas hacen de media 3 clicks en nuestra web, y entran desde la HOME. Entonces todo lo que esté a más del nivel 3, tiene mucha probabilidad de que no reciba muchas visitas. Y probablemente, estas URLs con nivel de profundidad tan alto, se posicionen peor.
Por otro lado, nos podemos hacer una idea de qué tan rápido se puede visitar tu web completa. Piensa que esto también influye para los robots indexadores. No tienen tiempo infinito para gastarlo en tu web.. ¿quizá tienes demasiadas URLs? O también una web con poco contenido tampoco es demasiado bueno para el posicionamiento..