Continuando con un post anterior sobre mostrar tablas de datos interactivas, o este otro relacionado sobre Datatables con botones de descarga.. traigo hoy otro code-kata, hecho en Symfony 4 para probar el Datatables más a fondo. En aquel post empecé a testear el Datatables con pocos datos. Datatables es un plugin de jQuery con el que en poco tiempo, listas, ordenas y filtras tablas de datos de forma muy profesional.
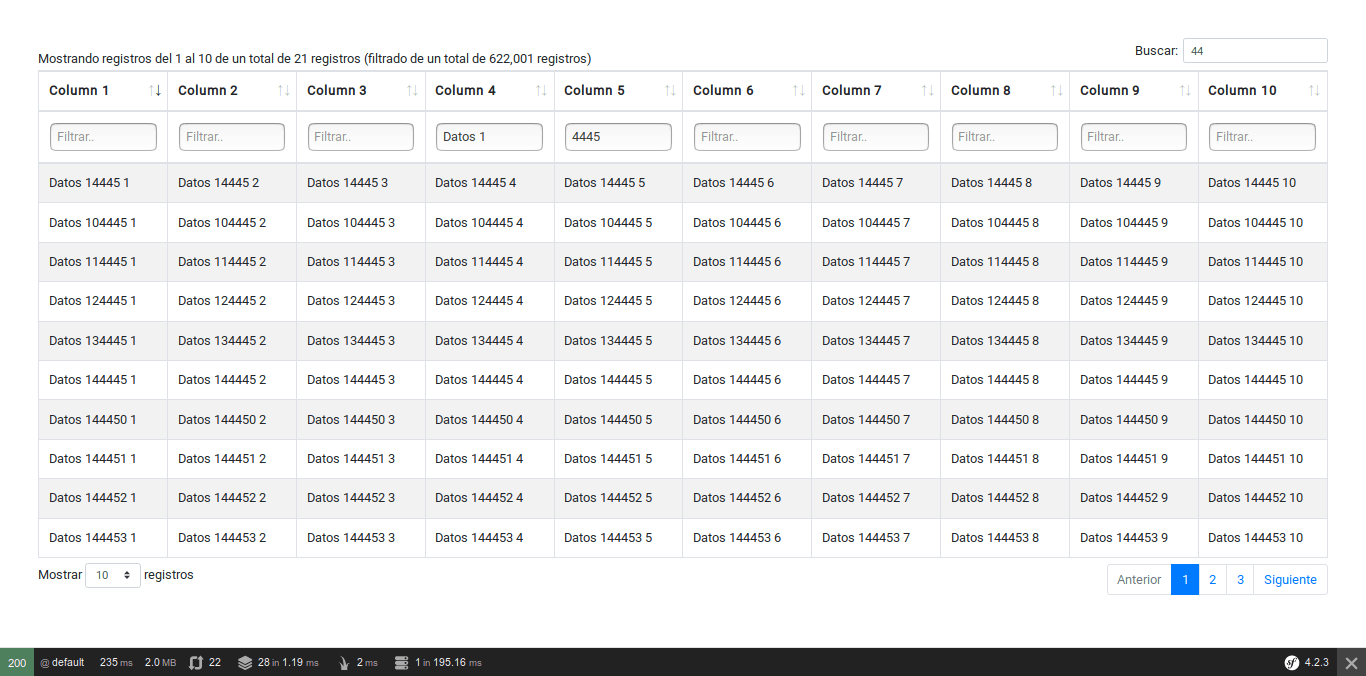
Ahora estoy probando cómo funciona sobre un proyecto con ingentes cantidades de datos, en concreto con una tabla con 622,001 registros. Llegado a éste extremo, no puedes cargar el 100% de los datos en el servidor, enviarlos al navegador, y pintarlos. Si lo haces, el navegador se sobrecargará, no podrá pintar la tabla, o irá muy muy lento.
Continuar leyendo..