Una buena práctica de programación es no usar los IDs de las bases de datos para identificar las cosas en los proyectos. Si no más bien usar un propio sistema de identificación, de forma que nosotros elijamos el identificador que va a tener un objeto antes de guardarlo en la base de datos, y sobre todo antes de enviarlo a sistemas remotos para su almacenaje.
Esto se aconseja hacer, por ejemplo, con los llamados UUIDs. Si en Sistemas Distribuidos es el mismo UUID para el mismo objeto de información en varios sistemas, se evitan muchos problemas. Porque tener que transmitir IDs distintos, y tener que casarlos constantemente entre los distintos sistemas informáticos es un problema..
Al grano, qué son los UUIDs
Significa Universal Unique IDentifier, identificador único universal. Es un sistema de identificación usando 5 cadenas alfanuméricas unidas por guiones de la forma:
XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX
Historia y más información aquí:
https://es.wikipedia.org/wiki/Identificador_%C3%BAnico_universal
Problemas de no definir UUIDs antes de guardar en la base de datos
Muchas veces, el proceso de identificación de registros en las BDs se hace de la siguiente manera:
- Se guarda registro en BD.
- Al haber guardado en BD, se ha auto-incrementado el ID, ya tenemos el que corresponde después de este guardado.
- Lo devolvemos a otros sistemas o procesos.
Por lo menos podemos tener los siguientes problemas:
- Proceso más lento, porque hasta no llegar al paso 3, el proceso que ha enviado el registro a guardar no obtiene el ID de la BD, y puede estar esperando.
- Inconsistencia en los datos, porque si hay fallo en algún punto del proceso, podemos volver a enviar los mismos datos a guardar. Con esto puede ocurrir, que si no identificamos desde el origen los datos, podemos tener finalmente en destino la misma información replicada, con IDs distintos.
- Tener objetos de información identificados de forma distinta en distintos sistemas, es un problema por tener que ir casando la información cada vez que saltamos de sistema.
Solución
Definir identificadores, por ejemplo, usando los propuestos por la Apolo Network Computing System y Distributed Computing Environment, los llamados UUIDs, antes de enviarlos a guardar en base de datos.
Es importante definirlos antes de enviar a guardar en base de datos. Incluso si se trata de Sistemas Distribuidos, definir estos UUIDs desde los sistemas remotos origen que envían la información inicial a guardar. Y en destino o base de datos, igualmente tratar como identificadores los definidos en origen, quizá incluso no generando unos nuevos identificadores en destino o base de datos.
Cómo se crean UUIDs, show me the code
En Python se podría hacer así:
import uuid;
print (uuid.uuid4())
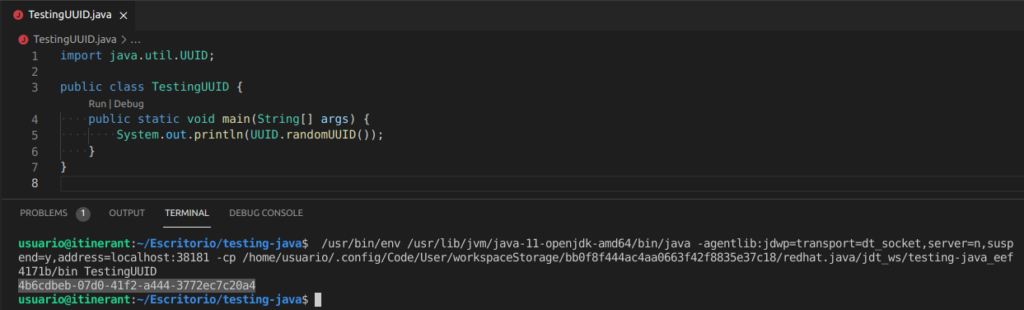
En Java se podría hacer con algo tal que así:
import java.util.UUID;
public class TestingUUID {
public static void main(String[] args) {
System.out.println(UUID.randomUUID());
}
}
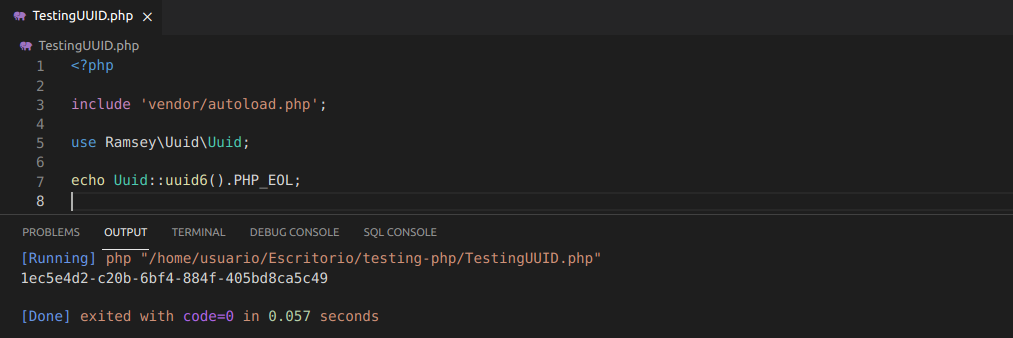
En PHP se podría hacer con algo tal que así, primero importando una librería:
composer require ramsey/uuid..el código fuente:
<?php
include 'vendor/autoload.php';
use Ramsey\Uuid\Uuid;
echo Uuid::uuid6().PHP_EOL;