Comparto aquí otro post apunte, un resumen, un howto para instalar la herramienta de línea de comandos de Drupal nombrada como drush. Esto sirve ya sea en local como en remoto en un servidor GNU/Linux.
Drush es el commandline de Drupal, que sirve para cosas similares a los CLI de Symfony, WordPress o la shell y commandline de Magento..
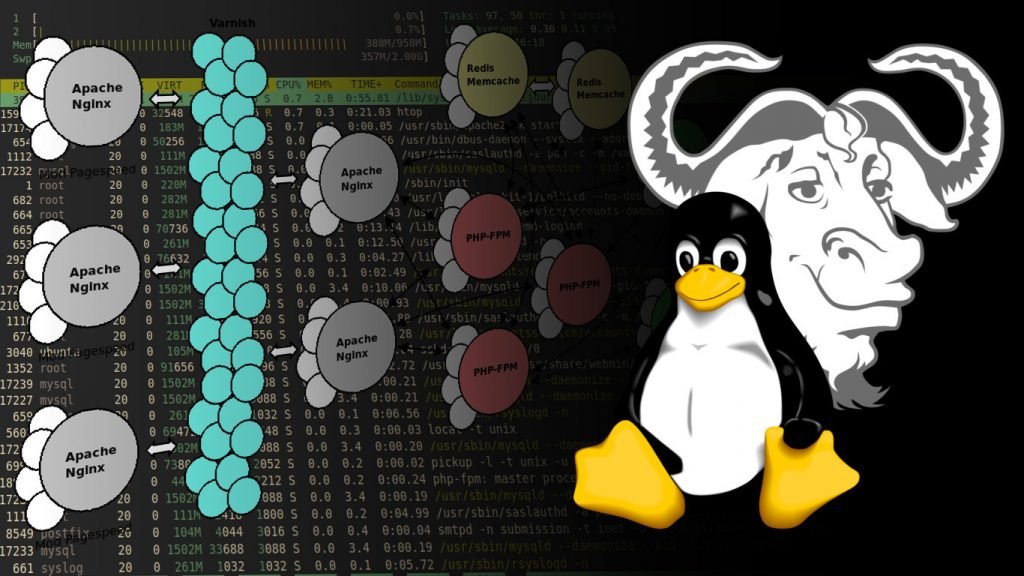
Aquí estoy de nuevo dejando mi granito de arena en todo esto de la informática. Hoy traigo un howto para la optimización de servidores web. Simplemente, son unas propuestas de configuraciones totalmente estándar y disponibles en las documentaciones oficiales. Pero que mejoran mucho el rendimiento de aplicaciones web, hechas en lenguajes como HTML, CSS, Javascript, PHP, Java, Python, SQL, DQL..
Este post es para optimizar aplicaciones web del tipo WordPress, Prestashop, Magento, Drupal, Symfony.. etcétera. Es una visión general de cómo funcionan las cosas a bajo nivel. Digo a bajo nivel, porque están muy de moda las arquitecturas server-less, o los servidores auto-administrados, aunque también necesiten su optimización. Pero aquí nos remangaremos la camisa, y nos embarraremos hasta el cuello mientras que vamos investigando, aprendiendo y aplicando, para cada proyecto en concreto. Este es un post para los que nos gusta trabajar los servidores, para los que nos gusta ponernos manos a la obra, para experimentar nosotros mismos con los proyectos, rascando cada milisegundo para conseguir que todo vaya lo más rápido posible..
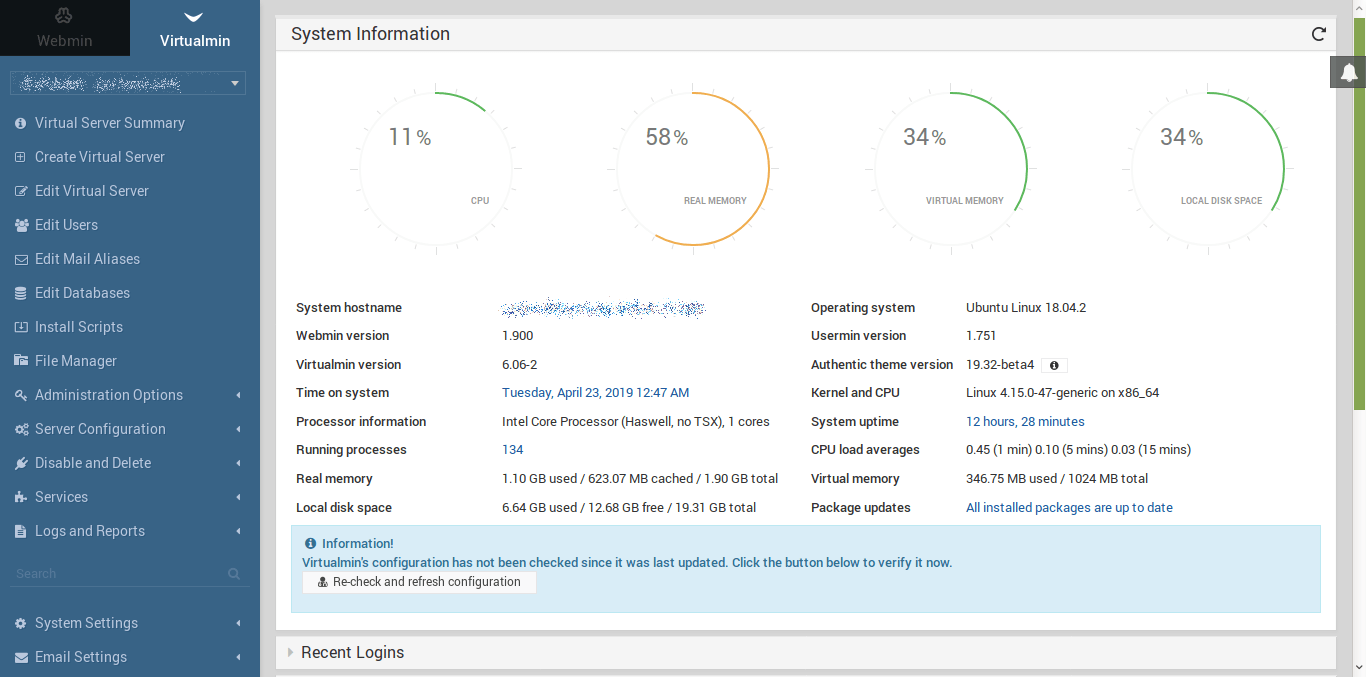
Llevo unos cuantos días sin escribir nada, pero es que intento sacar tiempo de debajo de las piedras y no hay manera. A ver si no pierdo las buenas costumbres y puedo seguir escribiendo más a menudo. El caso es que estoy revisando uno de los servidores que administro, para actualizarlo a la última versión, y optimizarlo tanto en costes como en rendimiento. Así que aquí estoy de nuevo compartiendo este sencillo HOWTO para migrar un servidor completo con Virtualmin.
Primero que todo tengo que presentar a Virtualmin para el que no lo conozca, es un panel de control del tipo Cpanel o Plesk. Funciona muy bien y tiene una versión gratuita con la que puedes tener correos electrónicos, antivirus, anti-spam, fail2ban, SSH, FTP, servidor de páginas web Apache, Mariadb, Mysql, Postgress, servidor de DNS.. etcétera.
¡Hola de nuevo! Últimamente estoy jugueteando mucho con Magento 2, poniéndome al día con todas las nuevas mejoras que trae. Cierto es que la gente por los foros habla de muchos problemas con las versiones 2.0, 2.1, 2.2.. Pero pienso que es normal, ya que se ha hecho un remake total de todo el código fuente de Magento.
Magento es un CMS para eCommerce enorme, tiene una gran cantidad de funcionalidades ya incorporadas de casa. Por otro lado, necesitas de un servidor potente para hacerlo correr. Pero tienes un punto de partida muy muy bueno, comparado por ejemplo con Prestashop, Sylius o WordPress con Woocommerce. Quizá incluso te puedes evitar un desarrollo a medida o la instalación de muchos módulos con sus correspondientes personalizaciones si es que Magento 2 ya dispone de las funcionalidades que necesitas.
He seguido jugando para ver hasta donde puede llegar este pequeño ordenador de poco más de 30€, la Raspberry Pi. Una joya de la informática, que junto a Syncthing, otra joya de la informática, hacen una combinación explosiva. Así que aquí estoy escribiendo éste HOWTO sobre servidores para montar una nube de terabytes de almacenamiento sincronizado y privado en tu propia casa, local o en varios lugares remotos.
Sólo por el coste de tus PCs, sin pagar nada a una empresa, sin que tus datos estén copiados en ordenadores que no son tuyos, y sin que tus datos estén copiados en el extranjero. Es decir, tus datos ya no tendrán que estar almacenados en ningún servidor externo en ninguna empresa. Todo sincronizado entre tus móviles, ordenadores y la Raspberry Pi. Además, podrás disfrutar de tantos terabytes como quieras sin coste mensual, sólo necesitas tener los discos externos que quieras y la Raspberry Pi encendida.
¡Hola de nuevo! Llevo unos días muy ajetreado y no he tenido tiempo de escribir nada en el blog, así que aquí estoy compartiendo de nuevo un pequeño HOWTO que me está ayudando mucho en el día a día. Se trata de un pequeño script en Shell Script que automatiza el despliegue en servidor de una aplicación web hecha con Symfony 4.
En Symfony 4 ha cambiado toda la estructura de directorios, así que para tenerlo todo bien controlado y evitar fallos intermitentes, esta es una de la cosas a automatizar. No es plan que cada vez que queramos hacer un despliegue en producción o en el área de pruebas tengamos que entrar al servidor, descargar la última versión, refrescar archivos temporales, etc..
Ahora vengo a compartir un pequeño, pero muy pequeño HOWTO. Se trata de un par de acciones para configurar los permisos de archivos y directorios en un servidor web Linux, y unas pocas explicaciones para saber el porqué hay que dar estos permisos..
La mayoría de los servidores web de Internet corren sobre sistemas operativos Linux. En estos sistemas operativos se establecen usuarios y los recursos del sistema operativos tienen unos permisos de acceso. De esta forma hay propietarios de los directorios y de los ficheros, con lo que los servidores web tienen que tener permiso para poder acceder a dichos ficheros. De lo contrario no podrán servir las páginas web.
Magento es un gran CMS para montar tiendas online. Está muy desarrollado teniendo en cuenta el SEO, el marketing, para tener muchos dominios con la misma web, muchas configuraciones de impuestos, de precios distintintos por web, distintas plantillas para cada sitio web.. todo desde un mismo panel de control.
Es tan flexible desde el mismo panel de control, que ha llegado a extremos de tal forma de que necesita todo tipo de cacheados, tablas temporales donde guardar indexada la información, así como también Varnish y Redis. Todo esto junto es una combinación explosiva y todo un reto hacerlo funcionar todo. Así que en este post vengo a hacer una review del funcionamiento de estos índices de datos.
De nuevo traigo otro CODE-KATA, para montar un blog en Symfony Flex, Symfony 4. Así en unos pocos minutos tenemos el esqueleto de lo que puede ser un blog. También valdría para hacer páginas corporativas, incluso si lo que queremos es un editor de fichas de productos también. Es decir, este es un pequeño tutorial para arrancar un nuevo proyecto en Symfony, creando es esqueleto de una aplicación web que va a ser un blog, con un editor de texto avanzado del tipo WYSIWYG.
WYSIWYG quiere decir What You See Is What You Get. Es decir, estos editores de texto son como los que tienen WordPress, Magento, Prestashop.. en donde se editan las páginas visualmente dentro del mismo navegador. Con este tipo de editores puedes organizar los textos, darles tamaño a las letras, alineación, subrayados, colores, etcétera.
Una respuesta a porqué Symfony es tan productivo son los comandos de consola. Con simples comandos podemos crear un proyecto nuevo, añadir nuevos componentes, lanzar un servidor de pruebas, chequear las URLs, crear entidades que vamos a guardar en base de datos, probar el envío de emails. También podemos modificar las tablas de datos, añadir nuevos elementos, editar los existentes, actualizar la base de datos, preparar nuevos elementos para almacenar, generar pantallas de listado de datos, ediciones de datos, borrados o creaciones. Generamos formularios automáticamente, con recepción de sus datos y guardado de dichos formularios en bases de datos. Podemos importar una base de datos de otro proyecto, generando todo el código fuente de una aplicación web que consulte los datos de dicha BD en apenas un rato. Podemos crear controladores, estructurando todas las zonas de la web, con sus plantillas, rutas, y URLs en poco tiempo. Y mucho más..
No tenemos que gastar tiempo en tediosas tareas repetitivas de construcción, y podremos centrarnos en lo especial de la aplicación web que estemos creando. Todas estas herramientas de generación de código las tenemos mediante comandos de consola. Cuantos más módulos añadas probablemente más comandos tendrás que te harán mucho más productivo. Te ahorrarán muchísimo tiempo, pero tienes que saber que estan ahí, saber cómo funcionan, y usarlos siempre que puedas. Hay que coger práctica con los comandos para aprovechar la productividad que te da Symfony. Continuar leyendo..
Continuando con el post anterior, traigo otro code-kata, o HOWTO, para hacer ping a una web, para empezar. Digo para empezar, porque esto no es más que el comienzo de una serie de acciones muy potentes sobre servidores web. Así podemos interactuar con un sitio web automática y remotamente. Este es uno de los mecanismos básicos de comunicación entre sistemas informáticos. Es decir, esto se puede reutilizar para que una web se comunique con otra web, con otro sistema informático, leyendo información o enviándola.
Para esto vamos a usar el gran CURL, que va muy bien para trabajar con el protocolo de las webs. Aunque como reza en su web, es compatible con muchos otros protocolos:
DICT, FILE, FTP, FTPS, Gopher, HTTP, HTTPS, IMAP, IMAPS, LDAP, LDAPS, POP3, POP3S, RTMP, RTSP, SCP, SFTP, SMB, SMBS, SMTP, SMTPS, Telnet and TFTP. curl supports SSL certificates, HTTP POST, HTTP PUT, FTP uploading, HTTP form based upload, proxies, HTTP/2, cookies, user+password authentication (Basic, Plain, Digest, CRAM-MD5, NTLM, Negotiate and Kerberos), file transfer resume, proxy tunneling and more..
Esta forma de hacer un simple ping web se puede escalar todo lo que quieras. Es decir, de esta forma es como trabajan internamente los módulos de métodos de pago, envío/lectura de feeds, las APIs de los CMSs, por ejemplo. Las acciones que se ejecutan mediante la comunicación con APIs sobre HTTP/HTTPS. Y claro, cómo no, para las archiconocidas y tan queridas API REST sobre HTTP. Todas estas acciones tienen un origen (cliente) y un destino (servidor).
Vamos a usar en este caso CURL, que es una herramienta del sistema operativo que podemos usar desde PHP. Si estás en GNU/Linux, puedes instalar tanto CURL como el módulo de PHP que lo usa así:
sudo apt-get install curl php7.2-curl
Si estás en Windows, Mac, o cualquier otro sistema operativo tendrás que ir a:
Si ejecutamos esto desde línea de comandos veremos algo tal que así:
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
<title>301 Moved Permanently</title>
</head><body>
<h1>Moved Permanently</h1>
<p>The document has moved <a href="https://jnjsite.com/">here</a>.</p>
</body></html>
El contenido de la web se está pintando por pantalla: jnjsite.com te invita a redirigirte a https://jnjsite.com que es la versión segura de la web.
Viendo información de la respuesta
Para esto podemos modificar el script anterior y sacamos mucha información de la respuesta:
En este caso nos está pidiendo hacer una redirección 301 a la web con HTTPS. En teoría deberíamos de seguir esta redirección. Así que..
Siguiendo redirecciones
Modificando el script anterior, tenemos haciendo las redirecciones lo siguiente:
<?php
$curlHandler = curl_init('jnjsite.com');
$response = curl_exec($curlHandler);
while(curl_getinfo($curlHandler)['http_code'] >= 300
and curl_getinfo($curlHandler)['http_code'] < 400){
// new URL to be redirected
curl_setopt($curlHandler, CURLOPT_URL, curl_getinfo($curlHandler)['redirect_url']);
$response = curl_exec($curlHandler);
}
var_dump(curl_getinfo($curlHandler));
curl_close($curlHandler);
Ejecutamos, y revisando por pantalla el resultado tendremos que finalmente se paran las redirecciones en https://jnjsite.com/ con un código de respuesta 200. He marcado en negrita lo nuevo con respecto al script anterior para redirigir hasta la página de destino.
Terminando
Para dejarlo limpio el script, sólo quedaría comprobar finalmente si la página ha dado un código OK de respuesta. Marco en negrita lo nuevo:
<?php
$curlHandler = curl_init('jnjsite.com');
curl_setopt($curlHandler, CURLOPT_RETURNTRANSFER, true);
curl_exec($curlHandler);
while (curl_getinfo($curlHandler)['http_code'] >= 300
and curl_getinfo($curlHandler)['http_code'] < 400) {
// new URL to be redirected
curl_setopt($curlHandler, CURLOPT_URL, curl_getinfo($curlHandler)['redirect_url']);
curl_exec($curlHandler);
}
if (curl_getinfo($curlHandler)['http_code'] >= 200
and curl_getinfo($curlHandler)['http_code'] < 300) {
echo 'OK'.PHP_EOL;
} else {
echo 'KO'.PHP_EOL;
}
curl_close($curlHandler);
A partir de aquí sólo queda hacer las acciones que consideres si tienes un OK o un KO.
Una tarea bastante importante a la hora de posicionar una página web es asegurarte de que sigues online. Si has contratado el alojamiento a una empresa no tendrás que preocuparte mucho por el estado del sistema operativo del servidor. Pero hay otros aspectos aparte del servidor que necesitan de tu atención. Puedes pensar que una página web basta con montarla con un buen CMS, que puedes dejarla online y ahí seguirá porque no hay razón para que deje de funcionar. Pues nada más lejos de la realidad, cuantas más cosas tenga tu web, más cosas pueden fallar.
Es decir, si tienes una página artesanal de un único fichero estático es difícil que deje de funcionar. Pero si tienes un CMS, quizá un WordPress, Prestashop, Drupal o Magento.. ya empiezas a tener más elementos que mantener. Los módulos pueden ser inestables, pueden engancharse las arañas de los buscadores, usuarios que llegan a bugs involuntariamente, etcétera.. No digamos ya si tienes muchas visitas que generan contenido dinámicamente.
Las páginas web son como los coches, necesitan un mantenimiento, unas revisiones. Sino, tarde o temprano, dejarán de funcionar. Así que si quieres curarte en salud, puedes tener un sencillo script que compruebe si sigue online una web.