¡Buenos días a todos! Voy a tratar de no perder las buenas costumbres, como esta de compartir en el blog mi granito de arena en todo esto de la informática. Hasta estos últimos días, que no he tenido la necesidad de mantener al día tantos servidores como últimamente. Estaba haciéndolo manualmente, a pelo como se suele decir, entrando en los servidores y aplicando actualizaciones, modificaciones, etc.. Todo esto es mucho tiempo así que delegar en un proveedor de hosting todo éste trabajo es una buena elección. Pero no siempre te va a valer y puede que necesites hacer configuraciones que un proveedor de hosting no te va a permitir. Administrar tu propio servidor no tiene que ser complejo.
Todo esto me ha llevado a investigar sobre paneles de control de servidores. Tenemos el gran Cpanel, Plesk, Zpanel, y un largo etcétera. Por temas laborales ya he probado algunos en los propios proveedores. Muchos funcionan de maravilla y son sencillos de gestionar. Pero no me voy a dedicar a alquilar hosts, sino que simplemente necesito mantener unos pocos servidores y no es viable comprar una solución comercial. Así que navegando y navegando al final me topé con Webmin.
Qué tiene
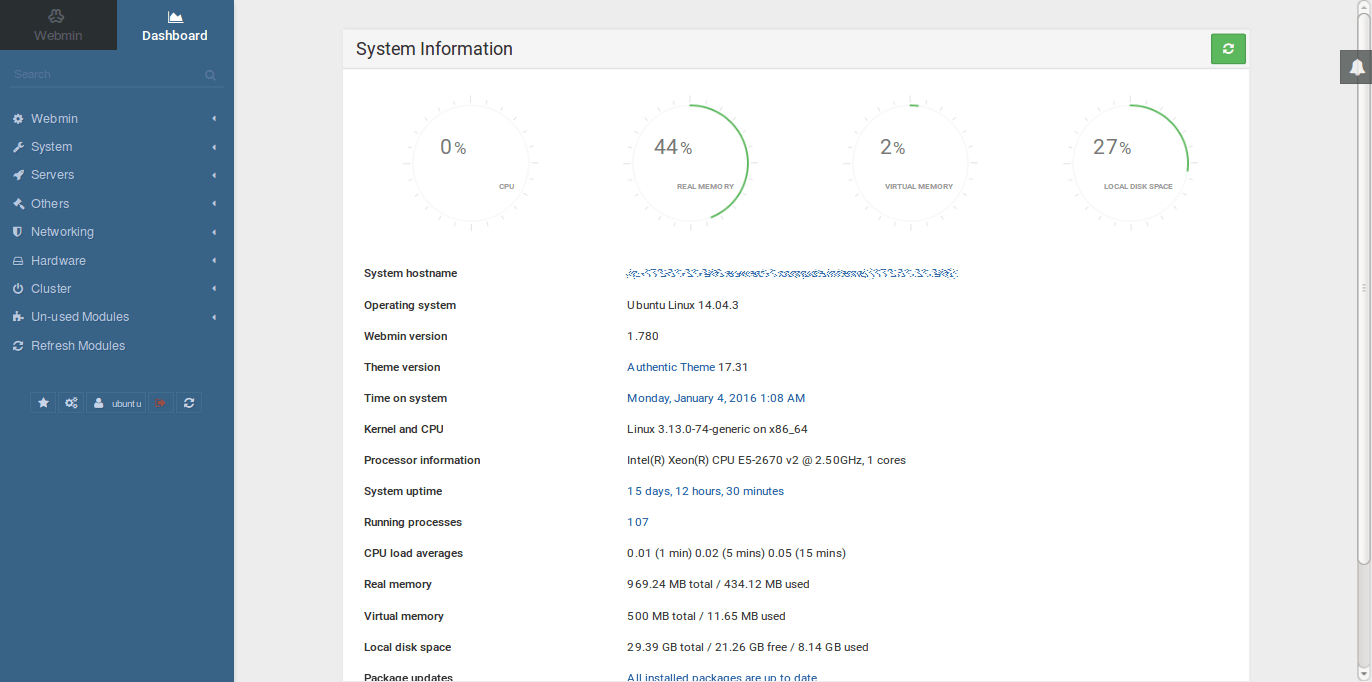
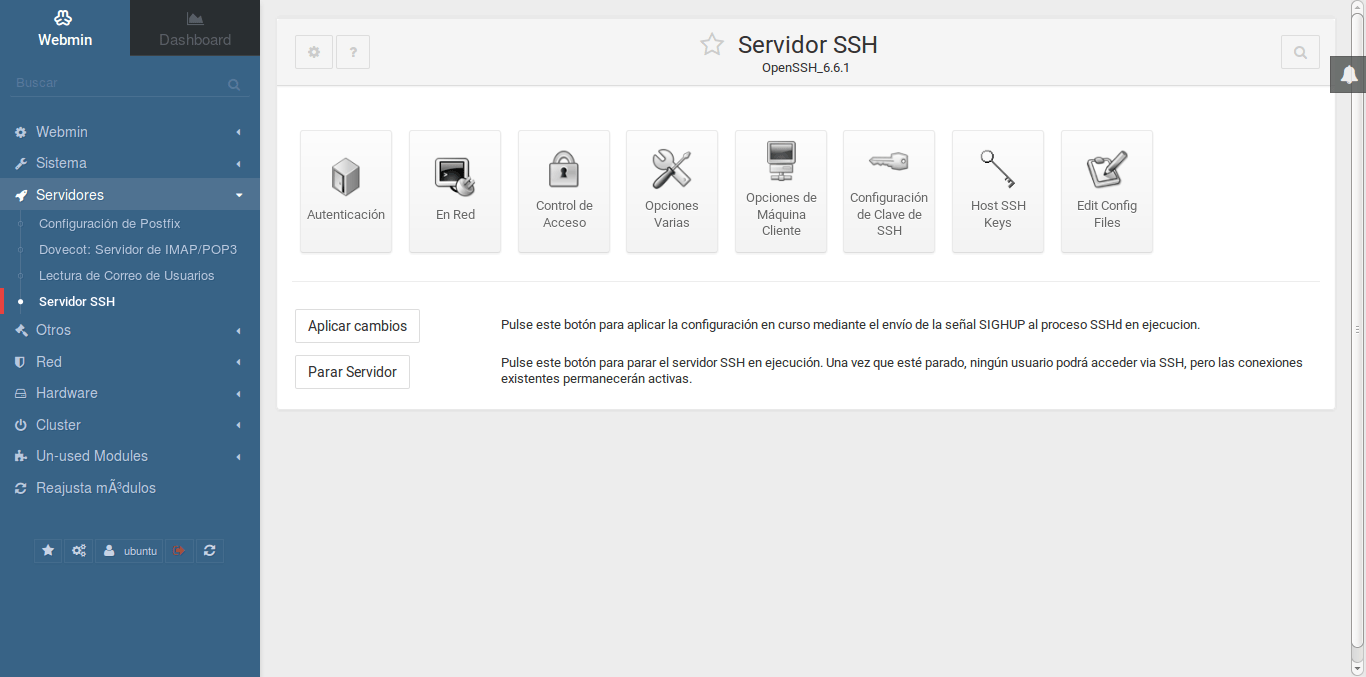
A grandes rasgos es una web desarrollada sobre Perl, que se instala en el puerto 10000 del servidor y se integra con el sistema operativo. Nos permite ver el estado del servidor, hacer configuraciones de red, actualizarlo, programar actualizaciones automáticas recibiendo informes a tu email. Te permite configurar usuarios, permisos, instalar bases de datos, servidor web, configurarlos. También hay módulos para instalar un servidor de correo electrónico. Puedes administrar Apache2, Mysql, Postgres, Postfix, Dovecod, etc, etc, etc.
La verdad es que te quedas mucho más tranquilo teniendo una herramienta de estas instalada en un servidor. No tienes más que entrar y de un vistazo puedes saber qué tal anda el sistema. Puedes aplicar las principales configuraciones y a correr que el tiempo es muy valioso.
Hay algunas tareas como la configuración hosts virtuales que haciéndolas a mano me he aclarado mejor. Pero deduzco que será cuestión de acostumbrarme al panel. Leo que hay extensiones de Webmin para configurar fácilmente hosts con varios dominios, permitiendo la lectura de correos a los usuarios proporcionándoles un panel de entrada al sistema.
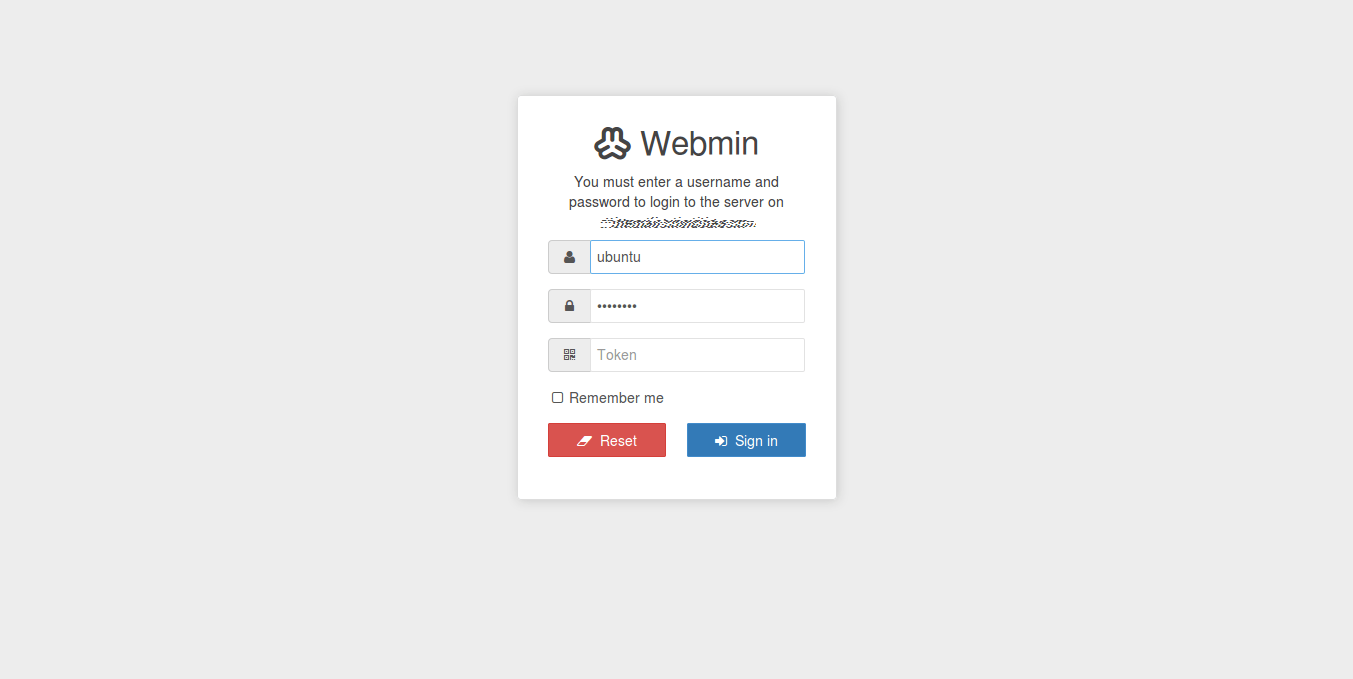
Un detalle que me ha gustado mucho es la autenticación en dos pasos (multi-factor authentication, MFA). Con el que podemos tener por ejemplo en nuestro móvil el Google Authenticator, y tener un código de seguridad extra que se genere a cada 30 segundos, para poder entrar como en la imagen siguiente:
El theme, piel, o plantilla que podéis ver en las imágenes no es el original. Es el ‘Authentic theme’ que me ha gustado también mucho. Es totalmente sensible al dispositivo (responsive), con lo que también podemos aplicar configuraciones sobre nuestro servidor desde el móvil o tablet, cosa que se agradece en gran manera.
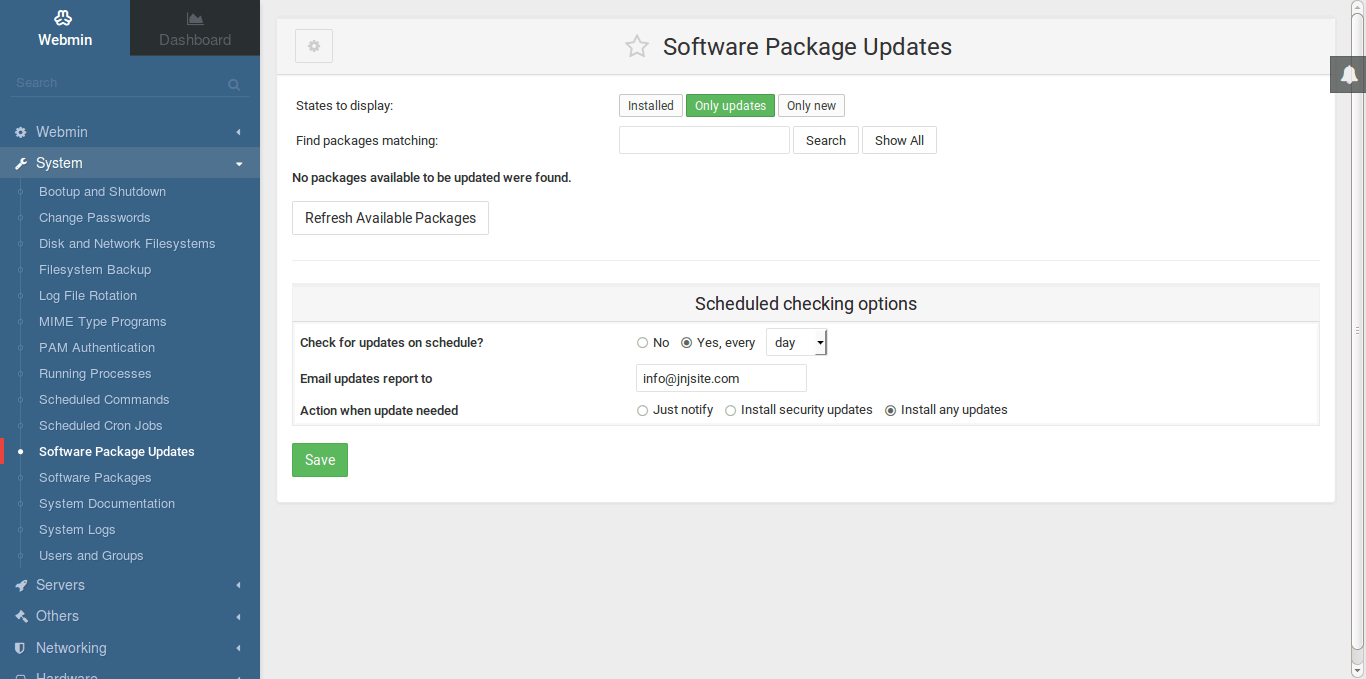
Aquí podemos ver lo sencillo que se hace mantener actualizado el sistema:
Aquí en la imagen se puede ver cómo configurar que todos los días se apliquen todas las actualizaciones del sistema, no sólo las de seguridad. Esto dispara cada día la instalación de todos los paquetes para actualizar y me envía un informe del resultado de la instalación a mi email. Ya os podéis hacer a la idea de que tiene muchas cosas, y lo tranquilo que me quedo con cada correo que recibo diciéndome que todo se ha actualizado correctamente.
Como buen usuario de Ubuntu, todas las pruebas y las imágenes que se ven son sobre Ubuntu. Me lo voy a anotar como indispensable en las nuevas instalaciones. Navegando y navegando por el menú lateral ya veo que no me lo voy a acabar, así que tendré que ver la documentación oficial de cada herramienta para ir más al grano en las tareas que se necesiten.
Terminando
Aquí la web oficial: http://webmin.com/
Es un proyecto alojado en Github, que por lo que veo se ve bien activo. Ahora mismo hace 4 horas que han subido una actualización, lo que denota que vamos a seguir teniendo actualizaciones frecuentemente, como todo buen proyecto Open Source.
Para el que quiera seguir investigando en esta joya de la informática, son interesantes los módulos Usermin y Virtualmin. No creo que tarde mucho en probarlos. De estos tenemos una versión gratuita y otra comercial, con las que vamos añadiendo más y más funcionalidades al panel de control.
¿Alguna sugerencia de otro programa similar para administrar servidores?