¡Hola de nuevo! Llevo unos días muy ajetreado y no he tenido tiempo de escribir nada en el blog, así que aquí estoy compartiendo de nuevo un pequeño HOWTO que me está ayudando mucho en el día a día. Se trata de un pequeño script en Shell Script que automatiza el despliegue en servidor de una aplicación web hecha con Symfony 4.
En Symfony 4 ha cambiado toda la estructura de directorios, así que para tenerlo todo bien controlado y evitar fallos intermitentes, esta es una de la cosas a automatizar. No es plan que cada vez que queramos hacer un despliegue en producción o en el área de pruebas tengamos que entrar al servidor, descargar la última versión, refrescar archivos temporales, etc..
Ahora vengo a compartir un pequeño, pero muy pequeño HOWTO. Se trata de un par de acciones para configurar los permisos de archivos y directorios en un servidor web Linux, y unas pocas explicaciones para saber el porqué hay que dar estos permisos..
La mayoría de los servidores web de Internet corren sobre sistemas operativos Linux. En estos sistemas operativos se establecen usuarios y los recursos del sistema operativos tienen unos permisos de acceso. De esta forma hay propietarios de los directorios y de los ficheros, con lo que los servidores web tienen que tener permiso para poder acceder a dichos ficheros. De lo contrario no podrán servir las páginas web.
Continuando con el post anterior sobre los índices de Magento, dejo aquí unas pocas explicaciones por si a alguien le sirve de cómo funcionan las tablas de reindex por dentro. El post anterior introducía el concepto de los índices de Magento, qué son, para qué sirven. Vamos a ver un poco más con unos casos de uso.
Magento es un gran CMS para montar tiendas online. Está muy desarrollado teniendo en cuenta el SEO, el marketing, para tener muchos dominios con la misma web, muchas configuraciones de impuestos, de precios distintintos por web, distintas plantillas para cada sitio web.. todo desde un mismo panel de control.
Es tan flexible desde el mismo panel de control, que ha llegado a extremos de tal forma de que necesita todo tipo de cacheados, tablas temporales donde guardar indexada la información, así como también Varnish y Redis. Todo esto junto es una combinación explosiva y todo un reto hacerlo funcionar todo. Así que en este post vengo a hacer una review del funcionamiento de estos índices de datos.
En este post de la serie de iniciación a Symfony, traigo una review del perfilador de Symfony, el profiler. Es una gran herramienta de desarrollo web que nos brinda Symfony. Podemos ver muchos datos internos de cómo funciona todo por dentro: la petición y respuesta, rendimiento, envío de formularios, validaciones, datos de las excepciones, logs… pasando por Doctrine, enrutamiento.. Continuar leyendo..
Ya tenemos el código fuente, ¿y ahora? ¿cuál es la magia que hace posible que un código fuente se ejecute?
Todo programa necesita un traductor, que compile o interprete el código fuente para que pueda ser ejecutado. Es una primera diferencia que puede marcarse entre los lenguajes de programación, ya que un lenguaje puede ser interpretado, compilado, o incluso ambas cosas. Además, la ejecución puede ser dependiente de la máquina, o ejecutarse en una máquina virtual, que te independiza de la máquina.
Por ejemplo los lenguajes funcionales o lógicos suelen usarse primeramente interpretados, como Prolog o Haskell mientras se desarrolla, pero también tenemos disponible un compilador para mejorar su eficiencia. PHP es interpretado, aunque ha habido compiladores para mejorar su eficiencia de ejecución. Cabe destacar como curiosidad la Hip Hop Virtual Machine de Facebook que crearon para agilizar PHP, que precisamente compila los ficheros fuente a un código objeto intermedio más rápido de ejecutar. Javascript, Typescript, Ruby, también son interpretados. C, C++, VB, C# son compilados, es decir, se necesita compilar el código fuente a códigos objeto, estos códigos objeto a su vez se linkan, se retraducen, para ejecutarse finalmente en la máquina.
Una respuesta a porqué Symfony es tan productivo son los comandos de consola. Con simples comandos podemos crear un proyecto nuevo, añadir nuevos componentes, lanzar un servidor de pruebas, chequear las URLs, crear entidades que vamos a guardar en base de datos, probar el envío de emails. También podemos modificar las tablas de datos, añadir nuevos elementos, editar los existentes, actualizar la base de datos, preparar nuevos elementos para almacenar, generar pantallas de listado de datos, ediciones de datos, borrados o creaciones. Generamos formularios automáticamente, con recepción de sus datos y guardado de dichos formularios en bases de datos. Podemos importar una base de datos de otro proyecto, generando todo el código fuente de una aplicación web que consulte los datos de dicha BD en apenas un rato. Podemos crear controladores, estructurando todas las zonas de la web, con sus plantillas, rutas, y URLs en poco tiempo. Y mucho más..
No tenemos que gastar tiempo en tediosas tareas repetitivas de construcción, y podremos centrarnos en lo especial de la aplicación web que estemos creando. Todas estas herramientas de generación de código las tenemos mediante comandos de consola. Cuantos más módulos añadas probablemente más comandos tendrás que te harán mucho más productivo. Te ahorrarán muchísimo tiempo, pero tienes que saber que estan ahí, saber cómo funcionan, y usarlos siempre que puedas. Hay que coger práctica con los comandos para aprovechar la productividad que te da Symfony. Continuar leyendo..
Continuando con el post anterior, traigo otro code-kata, o HOWTO, para hacer ping a una web, para empezar. Digo para empezar, porque esto no es más que el comienzo de una serie de acciones muy potentes sobre servidores web. Así podemos interactuar con un sitio web automática y remotamente. Este es uno de los mecanismos básicos de comunicación entre sistemas informáticos. Es decir, esto se puede reutilizar para que una web se comunique con otra web, con otro sistema informático, leyendo información o enviándola.
Para esto vamos a usar el gran CURL, que va muy bien para trabajar con el protocolo de las webs. Aunque como reza en su web, es compatible con muchos otros protocolos:
DICT, FILE, FTP, FTPS, Gopher, HTTP, HTTPS, IMAP, IMAPS, LDAP, LDAPS, POP3, POP3S, RTMP, RTSP, SCP, SFTP, SMB, SMBS, SMTP, SMTPS, Telnet and TFTP. curl supports SSL certificates, HTTP POST, HTTP PUT, FTP uploading, HTTP form based upload, proxies, HTTP/2, cookies, user+password authentication (Basic, Plain, Digest, CRAM-MD5, NTLM, Negotiate and Kerberos), file transfer resume, proxy tunneling and more..
Esta forma de hacer un simple ping web se puede escalar todo lo que quieras. Es decir, de esta forma es como trabajan internamente los módulos de métodos de pago, envío/lectura de feeds, las APIs de los CMSs, por ejemplo. Las acciones que se ejecutan mediante la comunicación con APIs sobre HTTP/HTTPS. Y claro, cómo no, para las archiconocidas y tan queridas API REST sobre HTTP. Todas estas acciones tienen un origen (cliente) y un destino (servidor).
Vamos a usar en este caso CURL, que es una herramienta del sistema operativo que podemos usar desde PHP. Si estás en GNU/Linux, puedes instalar tanto CURL como el módulo de PHP que lo usa así:
sudo apt-get install curl php7.2-curl
Si estás en Windows, Mac, o cualquier otro sistema operativo tendrás que ir a:
Si ejecutamos esto desde línea de comandos veremos algo tal que así:
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
<title>301 Moved Permanently</title>
</head><body>
<h1>Moved Permanently</h1>
<p>The document has moved <a href="https://jnjsite.com/">here</a>.</p>
</body></html>
El contenido de la web se está pintando por pantalla: jnjsite.com te invita a redirigirte a https://jnjsite.com que es la versión segura de la web.
Viendo información de la respuesta
Para esto podemos modificar el script anterior y sacamos mucha información de la respuesta:
En este caso nos está pidiendo hacer una redirección 301 a la web con HTTPS. En teoría deberíamos de seguir esta redirección. Así que..
Siguiendo redirecciones
Modificando el script anterior, tenemos haciendo las redirecciones lo siguiente:
<?php
$curlHandler = curl_init('jnjsite.com');
$response = curl_exec($curlHandler);
while(curl_getinfo($curlHandler)['http_code'] >= 300
and curl_getinfo($curlHandler)['http_code'] < 400){
// new URL to be redirected
curl_setopt($curlHandler, CURLOPT_URL, curl_getinfo($curlHandler)['redirect_url']);
$response = curl_exec($curlHandler);
}
var_dump(curl_getinfo($curlHandler));
curl_close($curlHandler);
Ejecutamos, y revisando por pantalla el resultado tendremos que finalmente se paran las redirecciones en https://jnjsite.com/ con un código de respuesta 200. He marcado en negrita lo nuevo con respecto al script anterior para redirigir hasta la página de destino.
Terminando
Para dejarlo limpio el script, sólo quedaría comprobar finalmente si la página ha dado un código OK de respuesta. Marco en negrita lo nuevo:
<?php
$curlHandler = curl_init('jnjsite.com');
curl_setopt($curlHandler, CURLOPT_RETURNTRANSFER, true);
curl_exec($curlHandler);
while (curl_getinfo($curlHandler)['http_code'] >= 300
and curl_getinfo($curlHandler)['http_code'] < 400) {
// new URL to be redirected
curl_setopt($curlHandler, CURLOPT_URL, curl_getinfo($curlHandler)['redirect_url']);
curl_exec($curlHandler);
}
if (curl_getinfo($curlHandler)['http_code'] >= 200
and curl_getinfo($curlHandler)['http_code'] < 300) {
echo 'OK'.PHP_EOL;
} else {
echo 'KO'.PHP_EOL;
}
curl_close($curlHandler);
A partir de aquí sólo queda hacer las acciones que consideres si tienes un OK o un KO.
Una tarea bastante importante a la hora de posicionar una página web es asegurarte de que sigues online. Si has contratado el alojamiento a una empresa no tendrás que preocuparte mucho por el estado del sistema operativo del servidor. Pero hay otros aspectos aparte del servidor que necesitan de tu atención. Puedes pensar que una página web basta con montarla con un buen CMS, que puedes dejarla online y ahí seguirá porque no hay razón para que deje de funcionar. Pues nada más lejos de la realidad, cuantas más cosas tenga tu web, más cosas pueden fallar.
Es decir, si tienes una página artesanal de un único fichero estático es difícil que deje de funcionar. Pero si tienes un CMS, quizá un WordPress, Prestashop, Drupal o Magento.. ya empiezas a tener más elementos que mantener. Los módulos pueden ser inestables, pueden engancharse las arañas de los buscadores, usuarios que llegan a bugs involuntariamente, etcétera.. No digamos ya si tienes muchas visitas que generan contenido dinámicamente.
Las páginas web son como los coches, necesitan un mantenimiento, unas revisiones. Sino, tarde o temprano, dejarán de funcionar. Así que si quieres curarte en salud, puedes tener un sencillo script que compruebe si sigue online una web.
Estos últimos días me han pedido sacar informes de un Magento. Ha sido muy interesante porque no me esperaba tener esta información en el CMS, pero sí, ahí estaba.
Resulta que Magento viene con un atributo de coste de los productos, que es de sistema. Dicho atributo de producto tiene el código cost. Además, en la información que se guarda en cada pedido tenemos el precio original, este coste del sistema en el momento de la venta, y más información. Con esto podremos saber el margen de beneficio que hubo en el momento de la venta.
Es importante notar que supongo que ya usas el atributo de coste del sistema, o que tienes un ERP enganchado a Magento que te lo está manteniendo actualizado con cada pedido de compra.
Magento es muy grande, aguanta carros y carretas, pudiéndole añadir gran cantidad de módulos. Uno de los proyectos en los que he participado alcanzó la friolera de 131 módulos, siendo algunos de estos módulos mega-módulos. Ha requerido mucho esfuerzo, todo hay que decirlo. Casi nunca suele ser «copiar y pegar los ficheros y ya está» como aquel que dice. Por el camino hay que resolver los conflictos, y tratamos día a día de evitar el añadir módulos si no es bien necesario. Hacemos limpieza de todos los que no se usen, y tratamos de actualizar todos los que se puedan, depende del tiempo que haya. Siempre surgen conflictos, y supone mucho tiempo hacer funcionar todas las opciones de ciertos módulos que entran en conflicto entre sí. Esto es el día a día del mantenimiento de los Magentos.
Origen de los problemas
Los desarrolladores hacen los módulos en un Magento limpio, recién instalado, sin que se requiera ningún otro módulo para su funcionamiento. Este es el entorno ideal, un Magento recién instalado. Pero la realidad nunca es así.
Siguiendo con el post anterior de bloqueo de IPs usando el cortafuegos integrado en el núcleo de Linux, llegamos a la necesidad de por ejemplo bloquear a cierto país. Hay negocios, o páginas web, que han recibido quizás ataques automáticos desde IPs que residen en Rusia, Rumanía o China. Si cerramos dicha entrada al servidor nos evitaríamos muchos problemas.
Tengamos en cuenta que si nuestro servidor trabaja con servidores que residen en estos países, podremos encontrarnos con conexiones que no se hacen, no dan respuesta al conectar, denegación de conexión.. Es complicado si nos olvidamos de que hemos bloqueado, por ejemplo, a Rusia. Si luego resulta que contratamos un servicio ruso, cuyos servidores residen en Rusia, estaremos contratando un servicio que no nos va a poder conectar.
Obteniendo IPs registradas por país
El primera paso es tener un listado de IPs del país en concreto que queremos bloquear. Para esto tenemos varias páginas que nos los sirven sin cargo. Por ejemplo:
Mejor coge los rangos de IPs del país que quieras bloquear usando el formato en CIDR. Es decir de la forma red/máscara, son así:
2.136.0.0/13
2.152.0.0/14
Tienes entonces que guardarte este listado de CIDRs de forma que tengas 1 CIDR por línea del fichero. Lo guardas en un fichero de texto, y se lo subes al servidor.
Metiendo el bloqueo en el firewall de Iptables
Para esto, desde un servidor GNU/Linux, bastará con ejecutar lo siguiente:
$ while read line; do sudo ufw deny from $line; done < IPsCountryCIDR.txt
Ahora hay que esperar mientras que se cargan todos los bloqueos en el cortafuegos. Tardará un buen rato porque UFW se encarga de transformar, línea a línea, al formato de Iptables.
Sólo nos quedará comprobar que está activo y con las reglas de bloqueo funcionando. Simulando una visita desde dicho país podremos comprobarlo.
Simulando visita desde cierto país
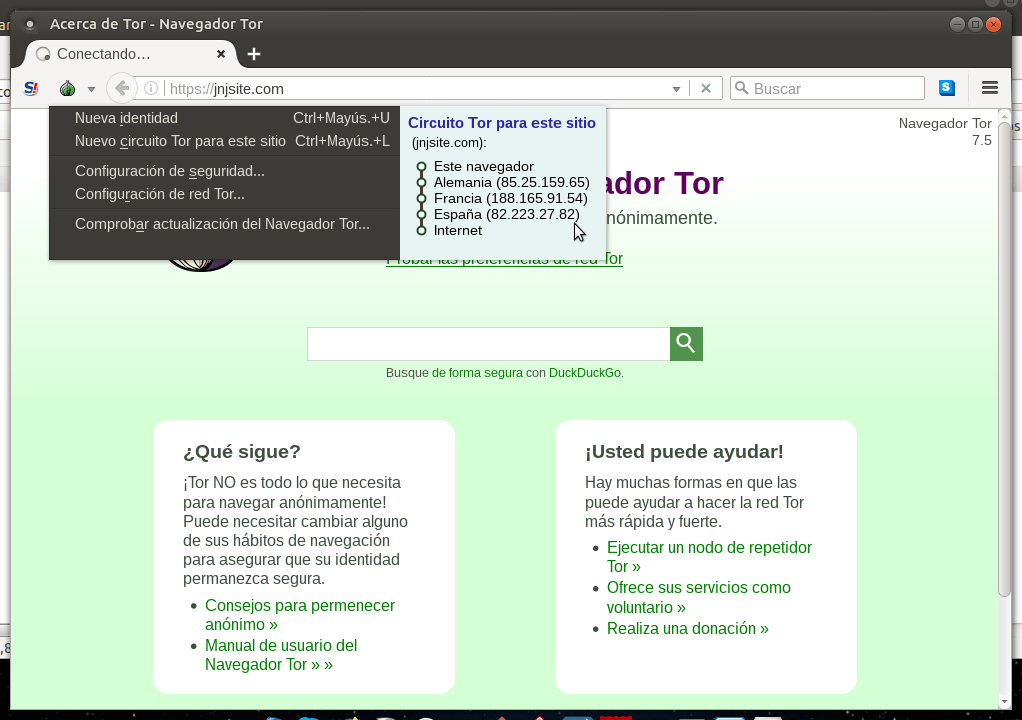
Para esto puedes usar el TorBrowser, del enrutamiento cebolla. Puedes descargártelo aquí:
https://www.torproject.org/
El navegador de la red Tor es un proyecto, que usando Firefox, hace que podamos navegar anónimamente. Esta anonimización la hace creando un camino de conexiones de varios nodos, desde nuestro PC, a la página destino. De esta manera podemos decirle al TorBrowser que queremos que el último nodo sea en un país concreto. Para esto abrimos el fichero este:
Browser/TorBrowser/Data/Tor/torrc
..y ponemos lo siguiente:
ExitNodes {es}
StrictNodes 1
El código entre llaves es el código del nodo final. Con esta configuración podemos visitar y ver esto en el navegador:
Terminando
Esto es todo, si has seguido todos los pasos, debes de haber podido bloquear el acceso a cierto país y comprobarlo con el TorBrowser.