Esta es la categoría general donde pongo los posts que no encajan con el resto de categorías. Y algunos posts, que aunque encajan en alguna otra categoría, también los he considerado de interés general en informática. Aquí puedes encontrar contenidos varios sobre utilidades como programas, sistemas operativos, herramientas de mantenimiento y cosas de este estilo que me han parecido interesantes.
Estas semanas atrás hemos tenido algunos problemas en algunos WordPress. Recurrentemente, las páginas web daban resultados en blanco. Era raro pues no teníamos registros de bloqueo. No había saltado el cortafuegos por poner mal las contraseñas. De repente, no teníamos servicio, otra web.. ahora el servicio de correo.. Un compañero de trabajo, luego otro.. Con cuentagotas iban reportando las incidencias. Tirando del hilo, tirando del hilo.. llegamos a la conclusión de que ¡todo en el servidor estaba fallando! ¡no puede ser!
Se trata de un servidor administrado en el que no tenemos que hacer ninguna gestión. El sistema operativo se mantiene actualizado automáticamente por la empresa que nos aloja. Siempre ha ido todo perfecto. El cambio siempre ha sido a mejor de todas las webs aquí alojadas.. Visto esto, y sabiendo que un WordPress sin actualizar puede ser origen de una ingente cantidad de problemas, me pongo manos a la obra. Reviso las actualizaciones de toooodos los WordPress que hay en este servidor. Uno a uno, actualizándolos todos manualmente. Me encontré con algunas actualizaciones que no se habían hecho, incluso teníamos un WordPress a medio actualizar que se había quedado enganchado. Varios proyectos heredados junto con otros nuevos. En fin, tareas rutinarias que hacer para poner todo al día..
Ahora mismo ya está todo arreglado y funcionando perfectamente. Cierto es que hemos tenido algunos problemas de rendimiento a nivel de sistema operativo. Pero por otro lado teníamos algunos WordPress que actualizar y poner al día. Así que, ahora que ya volvió el agua al río, y se arrojó luz sobre el origen de los problemas.. aquí estoy con algo de material nuevo.
Las nubes por definición son sistemas informáticos que crecen o decrecen según la necesidad. Son conjuntos de servidores/servicios que se adaptan a la demanda. Con todo esto, llegamos a una de las cosas más interesantes de AWS, el auto-escalado o la tolerancia a fallos, además de la personalización de los servidores. Podemos controlar la carga de los servidores que haya. Además automatizar el arranque y parada a ciertas horas de algunos de los servidores. O podemos duplicar los sistemas para evitar los ‘single point of failure como una casa’.
En OpsWorks tenemos herramientas muy interesantes relacionadas con esto. Algo rústicas, quizá clásicas dirían algunos. Pero gracias a ello, sin límites en la flexibilidad para configurar. Y si lo llevamos al extremo, este mismo sistema nos puede servir para automatizar la creación de nuestros servidores con herramientas como Chef y Kitchen. Todo esto y mucho más es lo que se puede hacer con el clásico OpsWorks.
Primero tendremos que ver qué son las AMIs. Cómo crear una manualmente o automáticamente. Y finalmente veremos cómo se usan, para hacernos una buena idea de qué podemos hacer en OpsWorks, y si es o no lo que necesitamos. Quizá es interesante ir a Docker con el EC2 Container Service o a CloudFormation, pero esto son otros temas..
No voy a entrar al detalle de cómo hacer cada cosa, no terminaría nunca. Así que si buscas una guía general para enfrentar después cada detalle poco a poco, este es tu post.
Ya puedes tener la estrategia de marketing mejor del mundo, la mejor campaña publicitaria, los mejores anuncios. Unas publicaciones excelentes en blogs, una gran inversión en SEM, o un SEO de contenidos inmejorable. Que si la infraestructura informática subyacente no acompaña de poco servirá. Aquí es donde entra el estar o no en la nube. Y nunca mejor dicho, poner tu aplicación web por las nubes.
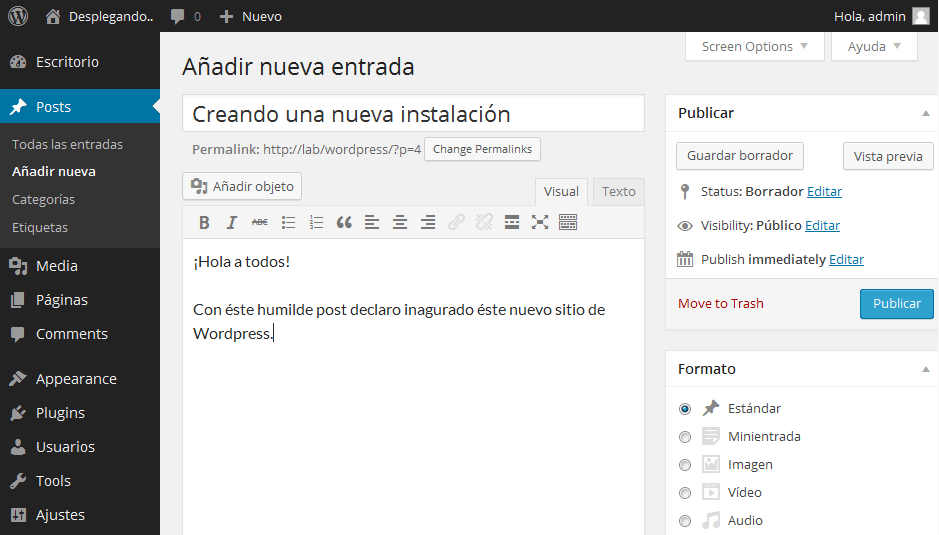
¡Hola de nuevo! Continuando con el post anterior sobre el desarrollo de temas para WordPress. Inevitablemente, ya sea más tarde o más temprano, llegaremos a querer desligarnos totalmente de modificar los temas de otros. Todos hemos empezado haciendo pequeños arreglos con el editor que tiene WordPress. Si has seguido el post anterior sobre cómo hacer un theme hijo de otro te habrás quedado con ganas de más, así que continuándolo vamos a crear uno básico 100% tuyo para lo que necesites.
Ahora bien, lo normal es que si estás aquí alguna vez hayas jugueteado con temas de WordPress de otros, modificándolos y llegando a un punto en el que no puedes actualizarlo porque perderías las modificaciones. Por otro lado si haces un tema hijo siempre vas a depender del padre, y también puede que haya actualizaciones del padre que rompan tu diseño. Así que la forma más profesional de solucionar esto es hacer tu propio tema, 100% tuyo, y totalmente desligado de cualquier otro.
¡Hola de nuevo! Estoy trabajando últimamente mucho con WordPress, así que he pensado que sería bueno ponerse al día indagando un poco más en cómo está hecho WordPress y cómo funcionan los llamados themes. Los themes son diseños que se pueden instalar en tu WordPress y lo hacen más atractivo a la vista, mejorando cosas de UI/UX que llaman los expertos. Es decir, mejoran el diseño, la interfaz de usuario, la usabilidad, la accesibilidad.. Estas materias en el desarrollo de software son principales para todos los que trabajamos con software con interfaz de usuario. Por esto que en la mayoría de estudios relacionados hemos tenido asignaturas destinadas única y exclusivamente a esta materia (Diseño web, Programación en Internet, Interfaces, Gráficos por computador..), algunas más hueso y otras más de sentido común.
Hoy traigo un pequeño HOWTO para limitar en el tiempo la cantidad de tareas a realizar. Necesitaba hacer un pequeño script para hacer 200 000 pequeñas tareas. El servicio sobre el que actúan éstas tareas está limitado a 12 por segundo, con lo que estábamos obligados a hacer algo para limitarlo en el tiempo y no ser bloqueados.
Este script puede servir para enviar una cola de emails transaccionales, para hacer un mailing a tus suscriptores sin pasarte de la cuota que tengas contratada con tu proveedor de hosting, también es útil para limitar la cantidad de veces por segundo que consumes de una API de algún servicio.
Las API REST son cada vez más habituales. Con HTTP tenemos las instrucciones básicas de listar, editar, crear o borrar. Es cada vez más habitual encontrarnos con estos servicios, o los antiguos Webservices o SOAP.. Habrá APIs con las que también si te pasas de tareas por segundo también te cierran para que no colapses el sistema y puedan dar servicio al resto. Así que pienso que si estás aquí te puede ser útil..
Hola de nuevo. Llevaba un tiempo dándole vueltas pero no encontraba el momento de llevarlo a cabo. Estaba pensando en unir entrebastidores.jnjsite.com y blog.jnjsite.com además de que tenía que mantener a la par jnjsite.com. Finalmente decidí por unirlo todo y llevarlo a un WordPress que es una excelente herramienta. Así me podré centrar en otras tareas como escribir entradas o atender lo demás que el tiempo corre.
Integración
Exporté las entradas de ambos blogs, las importé a un nuevo WordPress que se mantendrá actualizado automáticamente. A la vez las páginas informativas de mi página personal las he copiado y pegado en este nuevo sitio. Me decidí por un sencillo tema muy popular en el marketplace de WordPress, Customizr. Y la verdad que está quedando bastante bien ¿verdad?
Optimización
A esto le sumas la compresión de los códigos de estilo CSS, Javascripts y HTML. Junto con un acelerador mediante compilación de una caché de PHP a HTML de las zonas posibles. Todo junto me parece que está quedando bastante decente.
Espero que les guste y sigan visitándome los lectores del blog. Ahora tendré que ponerme con los temas de SEO jeje..
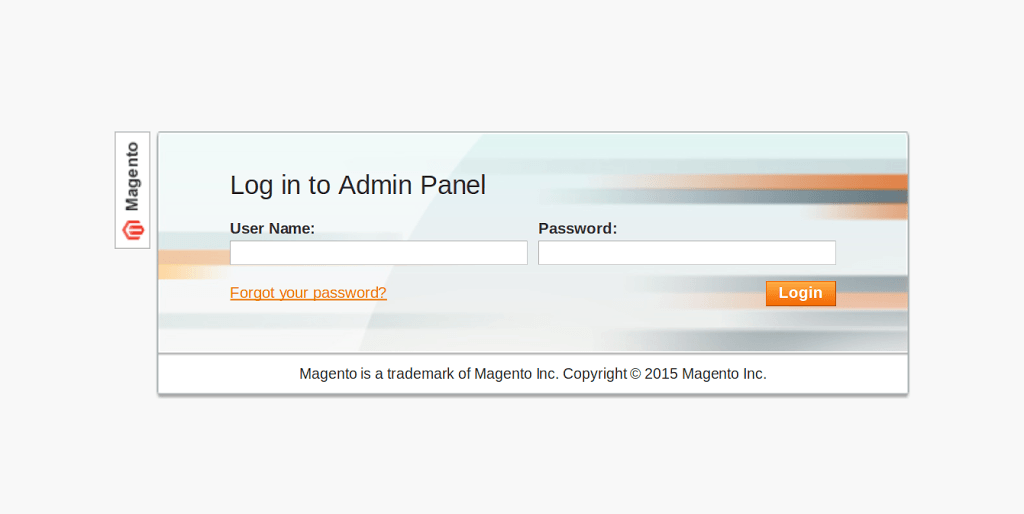
Ya estoy de nuevo por aquí frikeando un poco con el software. Estoy en estos días poniéndome al día con Magento. Es la gran solución de Código Libre para trabajar de forma económica montando una web. Entre las tres principales soluciones es la que de momento ostenta la primera posición, la segunda viene a ser Prestashop y la tercera WooCommerce.
Estoy hablando de las soluciones económicas, Open Source, PHP, robustas y estables. Ya si nos centramos sólo en España veremos que el despunte de tiendas online es para Prestashop. Espero no equivocarme con los datos, los puedes comprobar rápidamente haciendo un par de búsquedas y dejar un comentario abajo para corregir.
Situación
Resulta que tenemos entre manos ahora un Magento, pero no podemos entrar al panel de administración que lo tenemos en: https://nombredominio.com/index.php/admin
Pero sí que tenemos acceso a la base de datos. Es imprescindible tenerlo porque si no entonces tendremos que descartar éste mecanismo de recuperación. Necesitamos entonces acceso mediante phpMyAdmin, Mysql Workbench, línea de comandos..
Dónde tenemos que tocar
Ahora bien, los administradores están en la tabla admin_user y la contraseña de cada uno es la columna password. Si le hemos puesto un prefijo a las tablas entonces la tabla será de la forma prefijo_admin_user. Jeje, parece fácil pero ahora bien ¿qué cifrado se usa en Magento? Pues MD5, y se le añade una semilla al cifrado para hacerlo mejor.
Cómo cifra Magento las claves de administrador
Resumiendo, la estrategia es que pone una semilla delante de la contraseña. Si por ejemplo la semilla va a ser la palabra ‘semilla’ y la contraseña ‘thepass’ lo que hace es cifrar con MD5 la cadena ‘semillathepass’ y luego al resultado le añade después ‘:semilla’ y lo guarda.
Simplemente tenemos que ejecutar lo siguiente que hace esto que explico aquí arriba en el cliente de la base de datos Mysql y tendremos entonces la contraseña cambiada: UPDATE basededatos.prefijo_admin_user SET password=CONCAT(MD5(‘semillathepass’), ‘:semilla’) WHERE username=’administrador’;
Simplemente ejecutamos esto y se actualizará la clave del administrador ‘administrador’ poniéndole de clave ‘thepass’. Ya lo modificas a tu gusto y a correr 😉
¿Y las claves de usuarios clientes de la tienda?
Ahora bien, vamos a ir un paso más allá. Porque ¿dónde están las claves de los clientes? Éstas las tenemos en la tabla prefijo_customer_entity_varchar, y en prefijo_customer_entity tenemos los valores principales de los usuarios. Y en mi instalación estoy viendo que el atributo de identificador 12 corresponde a las claves de clientes. Que a su vez están cifradas de forma similar a las de administrador.
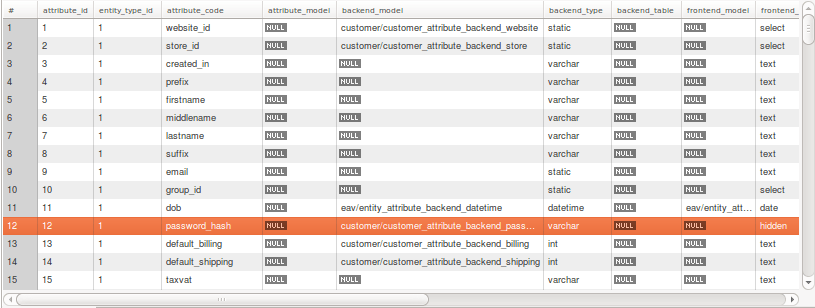
¿Pero qué tenemos aquí? ¿Porqué tenemos tantas tablas? ¿No sería mas sencillo una supertabla con una fila para cada usuario? Lo que ocurre es que Magento usa el modelo de datos EAV. Es un modelo de datos con el que los atributos que van a tener unos elementos se definen en una tabla, en otras se definen los principales valores de dichos elementos, y los valores disponibles se definen en otra tabla. Esto es engorroso para programar pero proporciona que se puedan definir en ejecución tantos valores como queramos de forma de que no se tengan que modificar ni códigos fuentes ni base de datos. Es muy potente, flexible, pero es engorroso y aumenta la complejidad.. a la hora de tocar base de datos o hacer consultas.
Es muy sencillo verlo de la siguiente forma. Tenemos la tabla de atributos prefijo_eav_attribute, si vemos un listado de algunos atributos podemos tener algo tal que así:
Fíjate que el atributo 12 es el password_hash. Ahora si vamos a los atributos de los customers que tenemos en la tabla prefijo_customer_entity_varchar y vemos los valores de las filas con attribute_id que sea 12 veremos que se parecen a contraseñas como las de los administradores ¿verdad?
Jeje, pues ya tenemos ahí las contraseñas. Parece que tenemos también la semilla después de los dos puntos concatenada con la clave. Será fácil entonces hacer otra consulta que actualice la contraseña de los usuarios de igual manera que la de los administradores.
UPDATE basededatos.prefijo_customer_entity_varchar SET password=CONCAT(MD5(‘semillathepass’), ‘:semilla’) WHERE value_id=1030;
Esta última consulta se supone que modificará la contraseña del cliente con identificador 175, es el valor 1030. A su vez el cliente que tendrá su email en la tabla prefijo_customer_entity y otros datos repartidos por sus tablas correspondientes.
Terminando
Ya lo dejo aquí, con el modelo de datos EAV, que es muy potente, tendremos disponibles todos los datos y podremos andar modificando no sólo las contraseñas de los clientes. Habrá que tener especial cuidado de no sobrecargar de consultas la base de datos, o hacerlo bien optimizándolas con JOINs en vez de concatenando tablas, no creando demasiados bucles que consultan datos y a su vez vuelven a consultar más datos con los resultados, etc.. porque fácilmente podemos relentizar en funcionamiento de nuestro Magento. Pero por otro lado tendremos un sistema muy potente para ir añadiendo lo que necesitemos si crear más y más tablas cada 2 por 3, con el consecuente peligro a la hora de actualizar cuando se añaden tablas o se modifica la base de datos.
Hola de nuevo. Aquí traigo otro pequeño HOWTO para automatizar la instalación de un servidor Postresql. Como ya indico en el post anterior, estoy jugueteando con Vagrant y necesito instalar la base de datos automáticamente para no tener que estar haciéndolo cada vez. Así que ya puestos a usar Vagrant o simplemente a usar la línea de comandos podemos ejecutar estos comandos para instalar y configurar Postgresql sin sufrir mucho y comenzar a trabajar lo antes posible.
Porqué Postgresql
Un compañero de trabajo me hizo una vez la pregunta, ¿porqué Postgresql?
Es un gigante de las bases de datos relacionales. Robusta como ella misma, soporta clustering, integridad referencial.. una cantidad ingente de características. En sus últimas versiones no tiene nada que envidiar al resto de bases de datos. Y mucho la catalogan como la mejor base de datos relacional Open Source. Además de que tenemos el pgAdmin que funciona a las mil maravillas.
https://es.wikipedia.org/wiki/PostgreSQL
Hay cantidad de información por Internet, ya que desde 1982 leo que está dando guerra, así que te puedes hacer una idea de si es o no una buena elección. Cada cual que mire cuáles son sus requisitos pues no es objetivo de este post hacer una comparativa.
Dónde está el script
Sin más preámbulos el script de instalación es el siguiente:
postgres_conf_file=»/etc/postgresql/9.3/main/postgresql.conf» postgres_pg_hba_file=»/etc/postgresql/9.3/main/pg_hba.conf» main() { apt-get -y install postgresql sudo -u postgres psql<<EOI password postgres postgres postgres q EOI sed -i «s/#listen_addresses = ‘localhost’/listen_addresses = ‘*’/g» ${postgres_conf_file} cat <<EOI > ${postgres_pg_hba_file} local all all md5 host all all 127.0.0.1/32 md5 host all all 10.0.2.2/32 md5 host all all ::1/128 md5 EOI service postgresql restart } main exit 0
A fecha en que escribo, este código se puede incluir en un Schell Script que por ejemplo podemos llamar instalarPostgresql.sh, darle permiso de ejecución y lanzarlo. Funciona con la versión que se instala actualmente en un servidor de producción con Ubuntu Server 14.04 que es la 9.3 de Postgresql si no me falla la memoria.
Simplemente instala el servidor, se conecta con el cliente psql para cambiar la contraseña del administrador postgres, escucha en todas las interfaces de red y permite conectar por red a 127.0.0.1 y a 10.0.2.2 que es la IP que se ve desde dentro de una máquina virtualizada con Vagrant.
Este es un pequeño HOWTO para instalar la base de datos. He estado jugueteando con Vagrant estos días probando como instalar automáticamente máquinas virtuales de forma automática, y me topé con el problema de cómo hacer un script que me instalara la BD en el sistema y que además dejara configurada la contraseña de administrador.
Este script funciona para Ubuntu 15.04, el cual te instala MariaDB 10.0 por defecto, que viene a ser la última versión estable de la aplicación.
MariaDB
Esta base de datos es un replace del archi-conocido MySQL pero al cual le han mejorado en varios aspectos. Es decir, tras la compra por parte de Oracle de MySQL, el equipo de desarrollo de la base de datos se separó continuando su desarrollo en lo que ahora se conoce como MariaDB.
Hay quien dice que Oracle pretendía estancar el desarrollo porque ya tiene sus propios productos de base de datos. Pueden haber sido diferencias de opiniones entre los desarrolladores. A saber cuál ha sido el porqué, el hecho es que MariaDB ha cogido fuerza. Por lo que la he probado funciona muy bien y tengo un servidor en producción que va muy bien hasta la fecha de hoy.
Al grano, el script
Esto a continuación se puede poner en un fichero, por ejemplo, llamado instalarMariaDB.sh y ejecutarlo: echo «######################################################################################» echo «# This script will install MariaDB and will set the root password.» echo «# It only works for first time execution. If it fails, check one command each time.» echo «######################################################################################»
sudo mysql -u root<<EOI use mysql; update user set plugin=» where User=’root’; update user set password=PASSWORD(«root») where User=’root’; flush privileges; quit EOI
sudo service mysql restart
Con esto ya dejo el ordenador y al sobre. Un saludo.
Imaginemos que somos mecánicos y tenemos un coche. Le estamos arreglando un faro, un faro que se ha roto o que alumbra poco o tiene un golpe. Ya tenemos la pieza de recambio, quitamos el faro antiguo y le ponemos el nuevo. Acto seguido ¿qué debemos hacer? ¿llamamos al dueño a que lo recoja directamente?
Tenemos mucha prisa porque estamos reparando una cosa tras otra. Nos han hecho una llamada de última hora y no nos hemos dado cuenta de que no hemos hecho las conexiones correctamente. Llega el dueño, va a arrancar y revienta un fusible porque no hemos hecho las conexiones bien. Ahora es cuando se nos cae la cara de vergüenza porque ni siquiera hemos arrancado el coche a ver si funcionaba el nuevo faro..
En el desarrollo de software es de vital importancia hacer los programas rápidamente, entregarlos en el tiempo y forma, además de que deben funcionar bien. Estas prisas nos pueden jugar malas pasadas pero hay soluciones profesionales, formas de trabajo para controlar o evitar estos problemas.
Pruebas unitarias y funcionales
Esto que le ha pasado al mecánico con prisas es lo mismo que nos puede pasar si entregamos un programa sin haber hecho las pruebas pertinentes. En el mundo del software existen, además de las pruebas manuales, formas de trabajo en las que se pueden tener una batería de pruebas automatizadas que prueben el buen funcionamiento de una aplicación.
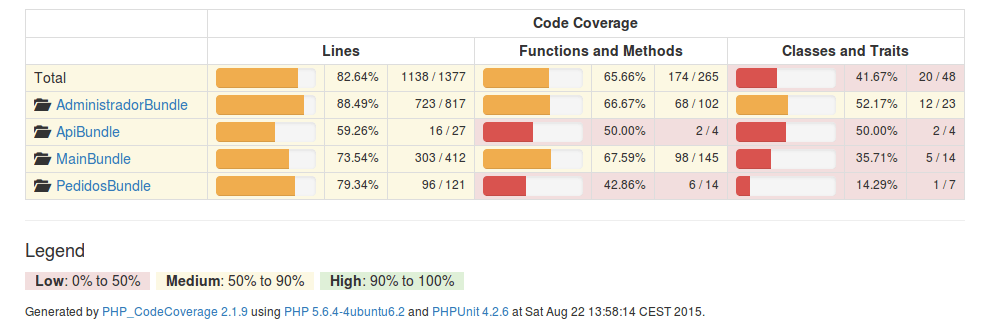
Por ejemplo, estoy empezando el desarrollo de un proyecto Open Source y tenemos ya el inicio de unas pruebas automatizadas. Los resultados de cobertura del código se pueden ver aquí:
http://obmscoverage.jnjsite.com/
Esto es el resultado de un navegador que simula un usuario que va probando las diferentes secciones de una aplicación web (programa web). El resultado mostrado es el Code Coverage, que significa cobertura del código. Es decir, es el porcentaje del programa que se ha probado navegando automáticamente por él sin que se funda ningún fusible 😉
Para el que quiera curiosear más en el programa que cito, el repositorio público está aquí:
https://github.com/obms/obms
Garantía de buen funcionamiento
Un nivel adecuado de cobertura oscila desde el 70% al 100%. Es muy tedioso alcanzar el 100%, y dependiendo de la naturaleza del software con un 70% – 80% será bastante. Pero si de ello dependen sistemas de vital importancia es aconsejable aumentar la cobertura al 100% o casi.
Esto a su vez evita que a medida que se va ampliando un programa, pasen desapercibidos errores nuevos al introducir nuevas mejoras en las aplicaciones web. Por esto es siempre bueno pedir los resultados de las pruebas automatizadas.
Integración Contínua (CI, Continuous Integration)
La integración continua es el sistema por el que todas estas pruebas automáticas se lanzan continuamente dando reportes de estado y alarmas para su supervisión.
Es un buen trabajo montar este sistema, pero una vez montado, la persona o el equipo de desarrollo se centrarán en desarrollar las nuevas funcionalidades, o en mantener el software.
Todo estará centralizado, organizado desde un punto desde el que, cada cierto tiempo se lanzarán automáticamente toda esta serie de pruebas automatizadas. También se suelen hacer a ciertas horas del día, o por la noche. Se podrán ver los resultados, con todo tipo de estadísticas. Se pueden automatizar análisis para buscar posibles problemas futuros, códigos fuentes duplicados. Se puede estudiar la mantenibilidad de un programa, entre otras cosas..
Para el proyecto anterior que cito, junto con las pruebas también se generan reportes de peligros o chequeos de estilo del código fuente:
http://obmscode.jnjsite.com/
También la documentación de la aplicación:
http://obmsdoc.jnjsite.com/
Aquí, el equipo o persona encargada de desarrollar, se podrá centrar en el análisis y programación puramente. Siempre que el sistema de Integración Contínua no de señales de alarma simplemente se puede continuar el trabajo, pudiendo dormir tranquilo.
Entregando
Aquí no termina todo, ahora tenemos un programa. Un programa que no da fallos, ha pasado las pruebas, tenemos alto porcentaje de cobertura, etc.. pero quedan otras tareas.
Una cosa es que el programa no de errores, y otra que haga lo que realmente tiene que hacer. Aquí es donde empezarán las pruebas de usuario, mantenimientos varios. Las llamadas pruebas de estrés, donde se mide la capacidad que tiene un programa. Es como si llevamos al circuito de carreras al coche con el que estamos trabajando para probarlo, damos unas cuantas vueltas viendo cómo va todo, su velocidad, frenada, etc.. Ahora sí que estaremos seguros al entregar el coche de que todo va a ir bien, o casi seguros.
Se quedan en el aire muchos conceptos pero no quiero extenderme demasiado y así tengo tema para otros posts 😉
Este es un pequeño HOWTO para tener de referencia.
Si tienes una relación entre dos entidades de la forma ManyToMany, una de ellas tendrá inversedBy y la otra mappedBy. Con un ejemplo se ve más claro.
Suponiendo que has generado las acciones CRUD con el comando siguiente:
$ php app/console doctrine:generate:crud
Supongamos que tenemos usuarios y negocios relacionados así, en una relación muchos a muchos. En la entidad Business tenemos: /** * @ORMManyToMany(targetEntity=»User», * inversedBy=»users», cascade={«persist»}) */ private $users;
Y en la entidad User tenemos:
/** * @ORMManyToMany(targetEntity=»Business», * mappedBy=»users», cascade={«persist»}) * @ORMJoinColumn(onDelete=»SET NULL») */ private $businesses; Ahora el editar los usuarios tenemos en el formulariode edición de un usuario lo siguiente:
->add(‘businesses’, ‘entity’, array( ‘by_reference’ => false, //.. )) La entidad inversedBy, que en este caso es Business, guardará correctamente los Users referenciados al editarlos. Pero al contrario con la entidad Users, tiene los Business mapeados, lo que hará que no guarde automáticamente las referencias.
Hay que añadir lo que he puesto en negrita en los códigos anteriores y en la entidad User lo siguiente para permitir que añada y borre los Business correctamente.
/** * Add businesses. * * @param AppBundleEntityBusiness $businesses * * @return User */ public function addBusiness(AppBundleEntityBusiness $business) { $this->businesses[] = $business; $business->addUser($this);
return $this; }
/** * Remove businesses. * * @param AppBundleEntityBusiness $businesses */ public function removeBusiness(AppBundleEntityBusiness $business) { $this->businesses->removeElement($business); $business->removeUser($this); }
Con ésto ya debe de funcionar. Si estamos editando un Business y añadimos o borramos Users lo hará correctamente, y de la forma inversa, si estamos editando un User, también añadirá o borrará Business.