Hoy traigo otro code-kata, esta vez para Magento y hecho en PHP. Se trata de un simple script que se lanza en línea de comandos. Con este script obtendremos primero todos los métodos de pago que se han usado al hacer los pedidos. Después, haremos un listado, por método de pago, y entre ciertas fechas, del monto de pedidos completados por método de pago.
Es decir, supongamos que queremos saber cómo han ido las ventas con el método de pago por tarjeta de crédito. O quizá queremos saber si la financiación es un método de pago que funciona bien. O quizá simplemente queremos tener el total de ventas entre fechas.
Pues todo esto es bastante sencillo sabiendo donde está cada cosa.
Métodos de pago usados en pedidos
A saber, los pedidos en Magento 1 guardan parte de sus datos principales en la tabla sales_flat_order. La información del método de pago utilizado en cada pedido se guarda en la tabla sales_flat_order_payment.
Entonces, sacando la columna method de la tabla sales_flat_order_payment tendremos todos los métodos de pago utilizados en los pedidos. Esto en lenguaje SQL queda así:
SELECT distinct(sfop.method) FROM sales_flat_order_payment sfop ORDER BY sfop.method ASC;
Ventas de los pedidos enviados
El siguiente paso será saber cómo sacar las cantidades de los pedidos completados. A saber, los pedidos completados se quedan con un status=complete y state=complete. Sí, es raro, Magento tiene internamente dos estados en cada pedido. Uno llamado status y otro llamado state. Estos estados están respectivamente en sus columnas. Así la consulta a la base de datos en SQL para sacar las ventas de un método de pago queda así:
SELECT sum(sfo.grand_total) total_sold
FROM sales_flat_order sfo
JOIN sales_flat_order_payment sfop ON sfop.parent_id = sfo.entity_id
WHERE sfo.state = 'complete' AND sfo.state = 'complete' AND sfop.method LIKE '".$methodCode."'
AND sfo.created_at > '".$startDate->format('Y-m-d H:i:s')."'
AND sfo.created_at < '".$endDate->format('Y-m-d H:i:s')."'"
Fíjate que la tabla sales_flat_order_payment se relaciona con sales_flat_order de la forma que marco en negrita.
El código completo
Ahora bien, haciendo un poco de ejercicio con un par de bucles, programando el script completo, nos queda algo tal que así:
<php
require_once __DIR__.'/app/Mage.php';
Mage::app()->setCurrentStore(Mage_Core_Model_App::ADMIN_STORE_ID);
// Loading arguments.
if ($argc == 3) {
$yearFrom = $argv[1];
$yearTo = $argv[2];
} else {
echo 'ERROR: Incorrect number of arguments.'.PHP_EOL;
exit;
}
$sqlConnection = Mage::getSingleton('core/resource')->getConnection('core_read');
// Loading available method codes.
$query = 'SELECT distinct(sfop.method)
FROM sales_flat_order_payment sfop
ORDER BY sfop.method ASC;';
$methods = $sqlConnection->fetchAll($query);
$methodCodes = array();
foreach ($methods as $method) {
$methodCodes[] = $method['method'];
}
//var_dump($methodCodes);
// Printing table in CSV format from January to December..
echo 'PAYMENT_METHOD';
for ($year = $yearFrom; $year <= $yearTo; ++$year) {
for ($month = 1; $month <= 12; ++$month) {
echo ','.$year.$month;
}
}
echo PHP_EOL;
foreach ($methodCodes as $methodCode) {
echo $methodCode;
for ($year = $yearFrom; $year <= $yearTo; ++$year) {
for ($month = 1; $month <= 11; ++$month) {
$startDate = new DateTime($year.'-'.$month.'-1 00:00:00');
//echo 'Date from: '.$startDate->format('Y-m-d H:i:s').PHP_EOL;
$endDate = new DateTime($year.'-'.($month + 1).'-1 00:00:00');
//echo 'Date to: '.$endDate->format('Y-m-d H:i:s').PHP_EOL;
$query = "SELECT sum(sfo.grand_total) total_sold
FROM sales_flat_order sfo
JOIN sales_flat_order_payment sfop ON sfop.parent_id = sfo.entity_id
WHERE sfo.state = 'complete' AND sfo.state = 'complete' AND sfop.method LIKE '".$methodCode."'
AND sfo.created_at > '".$startDate->format('Y-m-d H:i:s')."'
AND sfo.created_at < '".$endDate->format('Y-m-d H:i:s')."'";
$amount = $sqlConnection->fetchOne($query);
echo ','.$amount;
}
$startDate = new DateTime($year.'-12-1 00:00:00');
//echo 'Date from: '.$startDate->format('Y-m-d H:i:s').PHP_EOL;
$endDate = new DateTime($year.'-12-31 23:59:59');
//echo 'Date to: '.$endDate->format('Y-m-d H:i:s').PHP_EOL;
$query = "SELECT sum(sfo.grand_total) total_sold
FROM sales_flat_order sfo
JOIN sales_flat_order_payment sfop ON sfop.parent_id = sfo.entity_id
WHERE sfo.state = 'complete' AND sfo.state = 'complete' AND sfop.method LIKE '".$methodCode."'
AND sfo.created_at > '".$startDate->format('Y-m-d H:i:s')."'
AND sfo.created_at < '".$endDate->format('Y-m-d H:i:s')."'";
$amount = $sqlConnection->fetchOne($query);
echo ','.$amount;
}
echo PHP_EOL;
}
Este script tendremos que ponerlo en el directorio raiz del proyecto Magento para que enganche al Magento. Fíjate que necesita de dos parámetros de entrada que son el año de inicio y el año de fin. Además he marcado un objeto que proporciona Magento para estas cosas, la conexión a la base de datos que se guarda en $sqlConnection.
Ejecutando
Guardamos el script anterior en un fichero, por ejemplo llamado script.php. Si queremos las ventas desde el año 2017 al 2017, lo ejecutamos así desde línea de comandos:
$ php script.php 2017 2017
Veremos la salida por pantalla. Ahora bien, si redireccionamos la salida del script a un fichero, luego podremos visualizarlo mejor. Para esto lo ejecutamos así:
$ php script.php 2017 2017 > ventas_por_metodo_de_pago.csv
Ahora abrimos el fichero CSV con nuestro programa de hojas de cálculo favorito para ver los datos. Si no tienes, es muy recomendable el LibreOffice que lo puedes descargar gratis haciendo click aquí.
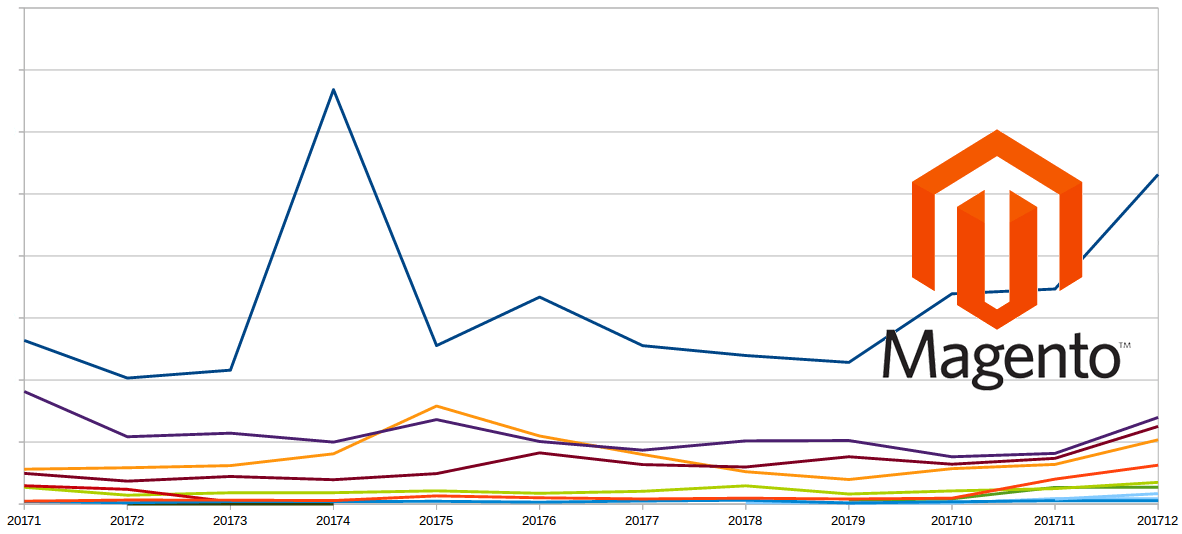
Así jugando un poco con los datos resultantes, podemos tener una gráfica de evolución de los métodos de pago. Como la imagen de cabecera de arriba. Podemos ver que algo está pasando en abril y por Navidades del año 2017 con uno de los métodos de pago.
Espero que sirva.
Un saludo.