Cuando tenemos un servidor visible desde Internet, desde cualquier lugar del mundo, recibimos visitas constantemente. Esperamos que estas visitas siempre sean las deseadas, pero quizá no lo son. No sólo hay personas y ordenadores con buenas intenciones conectados a Internet. También puede incluso haber sistemas informáticos mal configurados, que involuntariamente, ocasionen problemas a tus sistemas informáticos.
Por ejemplo, nos podemos encontrar con casos como estos:
- Una araña de un buscador, que escanea los contenidos de tu web con muy buenas intenciones, pero se engancha y no deja de escanearte llegando a bloquearte.
- Registro de usuarios ficticios, a modo de SPAM.
- Comentarios de SPAM con contenidos que enlazan a otras webs.
- Una web que se copia tus contenidos tratando de posicionarse en buscadores antes que tú.
- Y un largo etcétera.
Debemos de tener siempre nuestros servidores lo más actualizados posibles. Y sólo permitir la escucha en los puertos totalmente necesarios. Además de que sólo debemos de abrir los puertos para las IPs, o países que sean extrictamente necesarios.
Los escaneos automáticos en busca de vulnerabilidades en nuestros servidores va a ser constante, dalo por hecho. Si no lo haces, te arrepentirás más pronto que tarde, cuando la catástrofe haya acontecido. Así que los simples mortales como yo, que no somos expertos en ciberseguridad, debemos dejar trabajar a los que saben aplicando todas las actualizaciones lo antes posible, y sólo abriendo los puertos de escucha de los servicios estrictamente necesarios.
Cómo bloquear a estos visitantes
Ahora es cuando llegamos a Iptables. Iptables es un cortafuegos integrado en el núcleo de Linux. Es bastante engorroso de configurar así que han desarrollado utilizades que automatizan su configuración. Una utilidad muy interesante en GNU/Linux para manejar este cortafuegos es el UFW, que son las siglas de Uncomplicated FireWall.
Es bien sencillo de usar, por ejemplo para bloquear todas las conexiones que vengan de una IP basta con hacer lo siguiente:
$ sudo ufw deny from IP
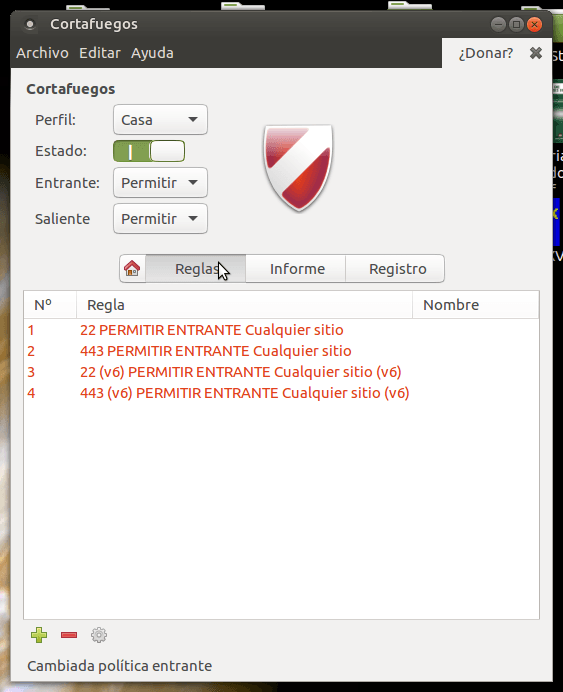
También tenemos incluso una interfaz gráfica del UFW, es el llamado GUFW, que se ve tal que así si tienes escritorio gráfico en el servidor:
Ahora bien, veamos los primeros pasos con este UFW desde línea de comandos. Ya que suponemos que estamos configurando un Servidor Ubuntu o basado en la distribución Debian.
Instalación
En Ubuntu 16 viene instalado por defecto. Si por lo que sea no lo tienes puedes hacer lo siguiente:
$ sudo apt-get install ufw
Para ver el estado en el que está podemos hacer:
$ sudo ufw status
Estado: inactivo
Perfecto, ya lo tenemos instalado, listo para activarlo.
Las configuraciones por defecto
Para hacer las primeras configuraciones tenemos el fichero /etc/default/ufw en donde tenemos estas dos configuraciones principales:
DEFAULT_INPUT_POLICY="DROP"
DEFAULT_OUTPUT_POLICY="ACCEPT"
Cuidado con esto, porque de estar configurando remotamente el cortafuegos, y no darte acceso a ti mismo, te puedes autodenegar el acceso y ya la hemos liado parda. El DEFAULT_INPUT_POLICY es la configuración de denegar por defecto las conexiones entrantes. Así que, podemos aceptar por defecto las configuraciones entrantes antes de activarlo si son las primeras pruebas que estamos haciendo.
Así que ponemos DEFAULT_INPUT_POLICY=»ACCEPT», o añadimos el permitir la entrada al puerto 22 para poder seguir trabajando remotamente. Si estas ya conectado a un servidor remoto, y quieres configurar esto, mejor dale una leída rápida a todo el post, para luego ir al grano de lo que necesites.
Algunas configuraciones
Así que vamos a arrancarlo:
$ sudo ufw enable
El cortafuegos está activo y habilitado en el arranque del sistema
Ahora vemos el estado de nuevo así:
$ sudo ufw status
Estado: activo
Ya lo tenemos en marcha. Vamos ahora con las configuraciones. Vamos a denegar el acceso a una IP:
$ sudo ufw deny from 1.2.3.4
Ahora vamos a aceptar todas las conexiones entrantes en los puertos 22, 80 y 443:
$ sudo ufw allow 22
$ sudo ufw allow 80
$ sudo ufw allow 443
Ok, ¿sencillo verdad? la verdad es que es mucho más sencillo que usar las tradicionales Iptables. Así que ahora listamos todo lo configurado:
$ sudo ufw status
Estado: activo
Hasta Acción Desde
----- ------ -----
Anywhere DENY 1.2.3.4
22 ALLOW Anywhere
80 ALLOW Anywhere
443 ALLOW Anywhere
22 (v6) ALLOW Anywhere (v6)
80 (v6) ALLOW Anywhere (v6)
443 (v6) ALLOW Anywhere (v6)
Imagina que ahora queremos borrar una regla. Lo más sencillo es listar numeradas las reglas y borramos:
$ sudo ufw status numbered
Estado: activo
Hasta Acción Desde
----- ------ -----
[ 1] Anywhere DENY 1.2.3.4
[ 2] 22 ALLOW IN Anywhere
[ 3] 80 ALLOW IN Anywhere
[ 4] 443 ALLOW IN Anywhere
[ 5] 22 (v6) ALLOW IN Anywhere (v6)
[ 6] 80 (v6) ALLOW IN Anywhere (v6)
[ 7] 443 (v6) ALLOW IN Anywhere (v6)
Ahora borramos la regla que permite conexiones entrantes al puerto 80 en el IPv4 así:
$ sudo ufw delete 3
Volvemos a listar para asegurarnos:
$ sudo ufw status numbered
Estado: activo
Hasta Acción Desde
----- ------ -----
[ 1] Anywhere DENY IN 1.2.3.4
[ 2] 22 ALLOW IN Anywhere
[ 3] 443 ALLOW IN Anywhere
[ 4] 22 (v6) ALLOW IN Anywhere (v6)
[ 5] 80 (v6) ALLOW IN Anywhere (v6)
[ 6] 443 (v6) ALLOW IN Anywhere (v6)
Borramos ahora las conexiones al puerto 80 en IPv6:
$ sudo ufw delete 5
Cómo hubiera sido con Iptables
Sólo como curiosidad, si quieres ver la configuración tradicional mediante Iptables, ejecuta lo siguiente para ver la tonelada de configuraciones que te has ahorrado mantener:
$ sudo iptables --list
Terminando
Espero que sirva como introducción, ya que el siguiente paso es bloquear las visitas por país. Si la has liado con alguna de las configuraciones, o simplemente quieres resetear todo, ejecutas esto y todo limpio:
$ sudo ufw reset