Traigo hoy un HOWTO para hacer landing pages sobre Symfony 4 orientadas a captación de clientes. Un code-kata con el que en menos de 1 hora tendremos la estructura básica funcional sobre Symfony 4 para recibir contactos, guardarlos en base de datos y enviárnoslos por email.
Llevo un par de semanas bien ajetreadas: migrando un proyecto desde Symfony 3 al 4, otro desde un Joomla en mal estado a Symfony 4, otro proyecto terminándolo de poner en marcha con Symfony 4. Pequeños proyectos de poco tiempo que me han dado muchas ideas para escribir. Así que, cargado de ideas, sigo poco a poco redescubriendo Symfony con Symfony 4. Y me sigo sintiendo como un niño con juguete nuevo 😀
Tengo que decir que Symfony 4 ha mejorado mucho en simplicidad. No hay que saberse cómo funciona todo el conjunto con los 50-60 componentes, ni gran parte de ellos, para comenzar a hacer aplicaciones web robustas: https://symfony.com/components Ni tampoco hay que hacer complicados tutoriales muy largos antes de comenzar a construir con Symfony. Eso sí, tenemos que tener claro cómo funciona la línea de comandos con PHP, y tener muy claro cómo funciona Composer, esto ya lo expliqué en el primer tutorial sobre Symfony 4. Si todavía no te manejas bien con Composer y la línea de comandos.. ¡será mejor que no sigas!
Vayamos al grano..
Comenzando
Pasando de la teoría, y partiendo de que ya hamos visto los posts anteriores, vamos a seguir los siguientes pasos:
- Preparar los componentes que necesitamos.
- Preparar la base de datos que va a almacenar los contactos.
- Pintar el formulario en la página de aterrizaje, o landing page para los amigos.
- Recibir el formulario.
- Guardar en base de datos.
- Y enviarlo a nuestro email.
Comencemos..
1. Preparando los componentes
Creamos el esqueleto del proyecto, entramos al directorio y ponemos los componentes que vamos a usar:
composer create-project symfony/skeleton symfony-tutorial-2
cd symfony-tutorial-2
composer require twig
composer require form
composer require security
composer require doctrine
composer require maker
composer require server
2. Preparando la base de datos
Para simplificar el proceso, y no tener que instalarnos localmente un motor de base de datos completo propongo usar SQLite. SQLite es un tipo de base de datos embebida en la aplicación. Esto quiere decir que no necesita de instalación, simplemente la aplicación creará un fichero y manejará los datos sin ningún otro programa intermediario.
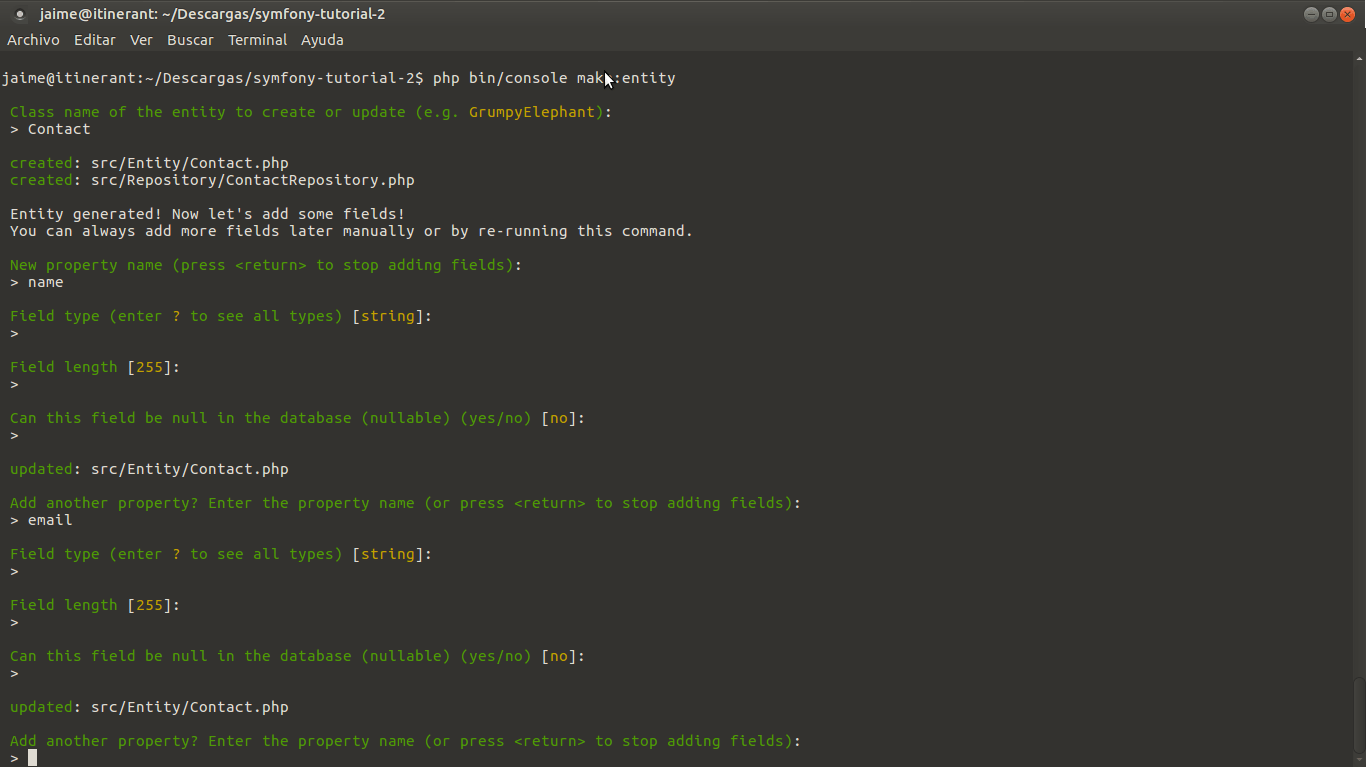
Primero vamos a crear la entidad Contact, que va a ser un objeto de PHP que va a almacenar los datos que un visitante nos deja en el formulario. A su vez, esta entidad se reutiliza para guardar automáticamente en la base de datos cada registro en una tabla que se creará automáticamente a partir de la entidad Contact. También se reutilizará para crear automáticamente el formulario. Esto de que Symfony genera automáticamente los códigos fuentes es brillante. Ejecutemos:
php bin/console make:entity
Y seguimos las instrucciones, vamos a crear los campos clásicos: nombre, email, asunto y mensaje.
Si te equivocas creando los campos no te preocupes, borra los ficheros y vuelve a empezar. Es la única forma de hacerlo y de aprender. Además, este comando make:entity te permite también añadir campos nuevos sobre la marcha si es que la entidad ya existe.
Ahora tenemos que decirle a la aplicación web que guarde los datos en SQLite, ya que por defecto los tratará de guardar en Mysql. Así que vamos a nuestro fichero .env y ponemos:
#DATABASE_URL=mysql://db_user:db_password@127.0.0.1:3306/db_name
DATABASE_URL=sqlite:///%kernel.project_dir%/var/data.db
Ahora las principales variables de configuración como contraseñas, parámetros de configuración, etc.. entran a la aplicación a modo de variables de entorno. Esto es más seguro y práctico, pero también es material para otro post. Ya está, ahora ejecutamos esto:
php bin/console doctrine:database:create
php bin/console doctrine:schema:create
Si todo ha ido bien, acabamos de crear el fichero data.db y la tabla Contact para guardar los contactos que nos hagan los visitantes.
3. Pintar el formulario en la página de aterrizaje
Vamos a simplificar todo, así que sólo tendremos una página que va a ser la home, en donde estará este formulario. Así creamos el controlador que recibe la visita:
php bin/console make:controller
Yo le he llamado MainController al mío y me crea los ficheros necesarios:
De nuevo Symfony nos ha hecho mucho trabajo. Podemos ya arrancar el servidor de desarrollo haciendo esto:
php bin/console server:start
Y vamos a ver los resultados en http://localhost:8000/
Para poner el formulario aquí vamos a editar el fichero symfony-tutorial-2/templates/main/index.html.twig y ponemos:
{% extends 'base.html.twig' %}
{% block title %}¡Creando landings!{% endblock %}
{% block body %}
{{ form(theForm) }}
{% endblock %}
Ahora mismo la plantilla intentará pintar el formulario llamado theForm pero no se lo hemos pasado, vamos a crearlo:
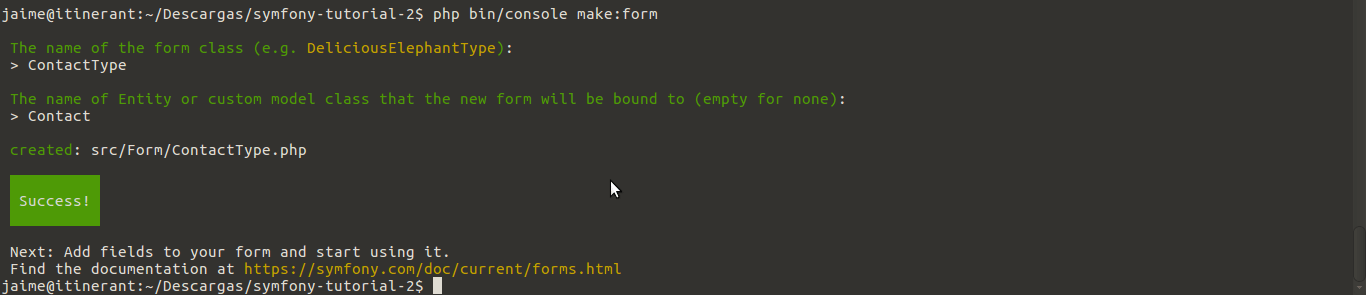
php bin/console make:form
Mira en la imagen, si le decimos a Symfony al crear el formulario que cargue de una entidad que ya hemos creado, Symfony creará todos los campos del formulario automáticamente. Así que ahora queda pasar con el controlador el formulario a la plantilla Twig. Editamos el fichero symfony-tutorial-2/src/Controller/MainController.php para que quede como lo siguiente:
<?php
namespace App\Controller;
use Symfony\Component\Routing\Annotation\Route;
use Symfony\Bundle\FrameworkBundle\Controller\Controller;
use App\Form\ContactType;
class MainController extends Controller
{
/**
* @Route("/", name="main")
*/
public function index()
{
$theForm = $this->createForm(ContactType::class);
return $this->render('main/index.html.twig', [
'theForm' => $theForm->createView(),
]);
}
}
Ya podemos recargar la página en el navegador y debemos ver el formulario. Sino, algo nos falta. Ahora nos queda recibir los formularios, guardarlos en base de datos y enviarnos estos datos a nuestro email.
4. Recibir el formulario
Si nos fijamos en el formulario, todavía no tiene botón de enviar, así que vamos a editar el fichero del formulario para añadírselo. En el fichero symfony-tutorial-2/src/Form/ContactType.php añadimos esta línea en los campos:
->add('submit', SubmitType::Class)
..y en la cabecera incluimos la clase del tipo submit así:
use Symfony\Component\Form\Extension\Core\Type\SubmitType;
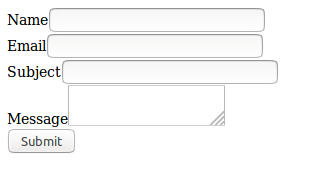
Refrescamos y nos sale el formulario listo para enviar los datos:
Ahora vamos a recibir los datos en el controlador. Para esto tenemos que recibir los datos en un objeto de PHP, del tipo de objeto que hemos creado antes. Es decir, vamos a usar la entidad Contact para que Symfony se encargue de todo. Es más fácil leer el código que explicarlo, en el controlador ponemos ahora:
<?php
namespace App\Controller;
use Symfony\Component\Routing\Annotation\Route;
use Symfony\Bundle\FrameworkBundle\Controller\Controller;
use App\Form\ContactType;
use App\Entity\Contact;
use Symfony\Component\HttpFoundation\Request;
class MainController extends Controller
{
/**
* @Route("/", name="main")
*/
public function index(Request $request)
{
$contact = new Contact();
$theForm = $this->createForm(ContactType::class, $contact);
$theForm->handleRequest($request);
if ($theForm->isSubmitted() && $theForm->isValid()) {
// save in database
// send email
}
return $this->render('main/index.html.twig', [
'theForm' => $theForm->createView(),
]);
}
}
He marcado en negrita lo que acabo de añadir. Con esto se recibe y se valida que los datos son correctos automáticamente. Es una maravilla, ¡Symfony se encarga de casi todo! Ya sólo nos queda guardar el contacto en la base de datos y enviárnoslo por email.
5. Guardar en la base de datos
Para guardarlo en la base de datos simplemente añadimos lo siguiente:
// save in database
$entityManager = $this->getDoctrine()->getManager();
$entityManager->persist($contact);
$entityManager->flush();
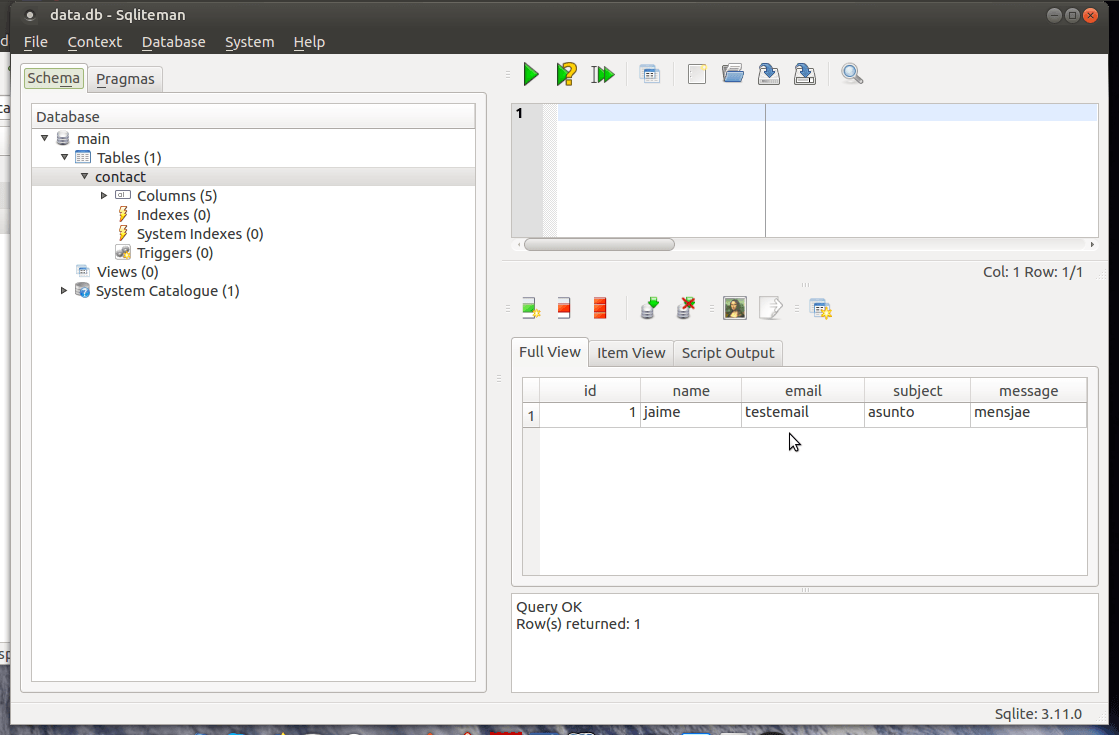
Ahora sí, probamos el formulario y nos lo enviamos. Tendremos que poder abrir el fichero de la base de datos para ver cómo se guardan estos datos en la tabla que corresponde. Tengo Sqliteman instalado para ver estos ficheros, que viene en los repositorios de Ubuntu, pero hay muchos gestores de SQLite. Con un gestor de ficheros SQLite podremos abrir el fichero symfony-tutorial-2/var/data.db y veremos algo parecido a esto:
Ya sólo nos quedaría enviárnoslo a nuestro email. Es sencillo pero vamos a dejarlo para el siguiente post, que este ya está quedando muy espeso. Además el envío de correos electrónicos tiene mucho juego y hoy no me queda más tiempo 🙂
¡Un saludo!