Este es un pequeño HOWTO para instalar la base de datos. He estado jugueteando con Vagrant estos días probando como instalar automáticamente máquinas virtuales de forma automática, y me topé con el problema de cómo hacer un script que me instalara la BD en el sistema y que además dejara configurada la contraseña de administrador.
Este script funciona para Ubuntu 15.04, el cual te instala MariaDB 10.0 por defecto, que viene a ser la última versión estable de la aplicación.
MariaDB
Esta base de datos es un replace del archi-conocido MySQL pero al cual le han mejorado en varios aspectos. Es decir, tras la compra por parte de Oracle de MySQL, el equipo de desarrollo de la base de datos se separó continuando su desarrollo en lo que ahora se conoce como MariaDB.
Hay quien dice que Oracle pretendía estancar el desarrollo porque ya tiene sus propios productos de base de datos. Pueden haber sido diferencias de opiniones entre los desarrolladores. A saber cuál ha sido el porqué, el hecho es que MariaDB ha cogido fuerza. Por lo que la he probado funciona muy bien y tengo un servidor en producción que va muy bien hasta la fecha de hoy.
Al grano, el script
Esto a continuación se puede poner en un fichero, por ejemplo, llamado instalarMariaDB.sh y ejecutarlo: echo «######################################################################################» echo «# This script will install MariaDB and will set the root password.» echo «# It only works for first time execution. If it fails, check one command each time.» echo «######################################################################################»
sudo mysql -u root<<EOI use mysql; update user set plugin=» where User=’root’; update user set password=PASSWORD(«root») where User=’root’; flush privileges; quit EOI
sudo service mysql restart
Con esto ya dejo el ordenador y al sobre. Un saludo.
Imaginemos que somos mecánicos y tenemos un coche. Le estamos arreglando un faro, un faro que se ha roto o que alumbra poco o tiene un golpe. Ya tenemos la pieza de recambio, quitamos el faro antiguo y le ponemos el nuevo. Acto seguido ¿qué debemos hacer? ¿llamamos al dueño a que lo recoja directamente?
Tenemos mucha prisa porque estamos reparando una cosa tras otra. Nos han hecho una llamada de última hora y no nos hemos dado cuenta de que no hemos hecho las conexiones correctamente. Llega el dueño, va a arrancar y revienta un fusible porque no hemos hecho las conexiones bien. Ahora es cuando se nos cae la cara de vergüenza porque ni siquiera hemos arrancado el coche a ver si funcionaba el nuevo faro..
En el desarrollo de software es de vital importancia hacer los programas rápidamente, entregarlos en el tiempo y forma, además de que deben funcionar bien. Estas prisas nos pueden jugar malas pasadas pero hay soluciones profesionales, formas de trabajo para controlar o evitar estos problemas.
Pruebas unitarias y funcionales
Esto que le ha pasado al mecánico con prisas es lo mismo que nos puede pasar si entregamos un programa sin haber hecho las pruebas pertinentes. En el mundo del software existen, además de las pruebas manuales, formas de trabajo en las que se pueden tener una batería de pruebas automatizadas que prueben el buen funcionamiento de una aplicación.
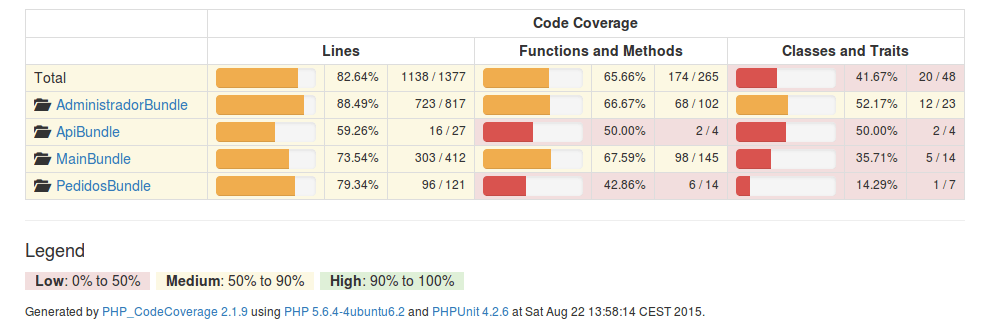
Por ejemplo, estoy empezando el desarrollo de un proyecto Open Source y tenemos ya el inicio de unas pruebas automatizadas. Los resultados de cobertura del código se pueden ver aquí:
http://obmscoverage.jnjsite.com/
Esto es el resultado de un navegador que simula un usuario que va probando las diferentes secciones de una aplicación web (programa web). El resultado mostrado es el Code Coverage, que significa cobertura del código. Es decir, es el porcentaje del programa que se ha probado navegando automáticamente por él sin que se funda ningún fusible 😉
Para el que quiera curiosear más en el programa que cito, el repositorio público está aquí:
https://github.com/obms/obms
Garantía de buen funcionamiento
Un nivel adecuado de cobertura oscila desde el 70% al 100%. Es muy tedioso alcanzar el 100%, y dependiendo de la naturaleza del software con un 70% – 80% será bastante. Pero si de ello dependen sistemas de vital importancia es aconsejable aumentar la cobertura al 100% o casi.
Esto a su vez evita que a medida que se va ampliando un programa, pasen desapercibidos errores nuevos al introducir nuevas mejoras en las aplicaciones web. Por esto es siempre bueno pedir los resultados de las pruebas automatizadas.
Integración Contínua (CI, Continuous Integration)
La integración continua es el sistema por el que todas estas pruebas automáticas se lanzan continuamente dando reportes de estado y alarmas para su supervisión.
Es un buen trabajo montar este sistema, pero una vez montado, la persona o el equipo de desarrollo se centrarán en desarrollar las nuevas funcionalidades, o en mantener el software.
Todo estará centralizado, organizado desde un punto desde el que, cada cierto tiempo se lanzarán automáticamente toda esta serie de pruebas automatizadas. También se suelen hacer a ciertas horas del día, o por la noche. Se podrán ver los resultados, con todo tipo de estadísticas. Se pueden automatizar análisis para buscar posibles problemas futuros, códigos fuentes duplicados. Se puede estudiar la mantenibilidad de un programa, entre otras cosas..
Para el proyecto anterior que cito, junto con las pruebas también se generan reportes de peligros o chequeos de estilo del código fuente:
http://obmscode.jnjsite.com/
También la documentación de la aplicación:
http://obmsdoc.jnjsite.com/
Aquí, el equipo o persona encargada de desarrollar, se podrá centrar en el análisis y programación puramente. Siempre que el sistema de Integración Contínua no de señales de alarma simplemente se puede continuar el trabajo, pudiendo dormir tranquilo.
Entregando
Aquí no termina todo, ahora tenemos un programa. Un programa que no da fallos, ha pasado las pruebas, tenemos alto porcentaje de cobertura, etc.. pero quedan otras tareas.
Una cosa es que el programa no de errores, y otra que haga lo que realmente tiene que hacer. Aquí es donde empezarán las pruebas de usuario, mantenimientos varios. Las llamadas pruebas de estrés, donde se mide la capacidad que tiene un programa. Es como si llevamos al circuito de carreras al coche con el que estamos trabajando para probarlo, damos unas cuantas vueltas viendo cómo va todo, su velocidad, frenada, etc.. Ahora sí que estaremos seguros al entregar el coche de que todo va a ir bien, o casi seguros.
Se quedan en el aire muchos conceptos pero no quiero extenderme demasiado y así tengo tema para otros posts 😉
Este es un pequeño HOWTO para tener de referencia.
Si tienes una relación entre dos entidades de la forma ManyToMany, una de ellas tendrá inversedBy y la otra mappedBy. Con un ejemplo se ve más claro.
Suponiendo que has generado las acciones CRUD con el comando siguiente:
$ php app/console doctrine:generate:crud
Supongamos que tenemos usuarios y negocios relacionados así, en una relación muchos a muchos. En la entidad Business tenemos: /** * @ORMManyToMany(targetEntity=»User», * inversedBy=»users», cascade={«persist»}) */ private $users;
Y en la entidad User tenemos:
/** * @ORMManyToMany(targetEntity=»Business», * mappedBy=»users», cascade={«persist»}) * @ORMJoinColumn(onDelete=»SET NULL») */ private $businesses; Ahora el editar los usuarios tenemos en el formulariode edición de un usuario lo siguiente:
->add(‘businesses’, ‘entity’, array( ‘by_reference’ => false, //.. )) La entidad inversedBy, que en este caso es Business, guardará correctamente los Users referenciados al editarlos. Pero al contrario con la entidad Users, tiene los Business mapeados, lo que hará que no guarde automáticamente las referencias.
Hay que añadir lo que he puesto en negrita en los códigos anteriores y en la entidad User lo siguiente para permitir que añada y borre los Business correctamente.
/** * Add businesses. * * @param AppBundleEntityBusiness $businesses * * @return User */ public function addBusiness(AppBundleEntityBusiness $business) { $this->businesses[] = $business; $business->addUser($this);
return $this; }
/** * Remove businesses. * * @param AppBundleEntityBusiness $businesses */ public function removeBusiness(AppBundleEntityBusiness $business) { $this->businesses->removeElement($business); $business->removeUser($this); }
Con ésto ya debe de funcionar. Si estamos editando un Business y añadimos o borramos Users lo hará correctamente, y de la forma inversa, si estamos editando un User, también añadirá o borrará Business.
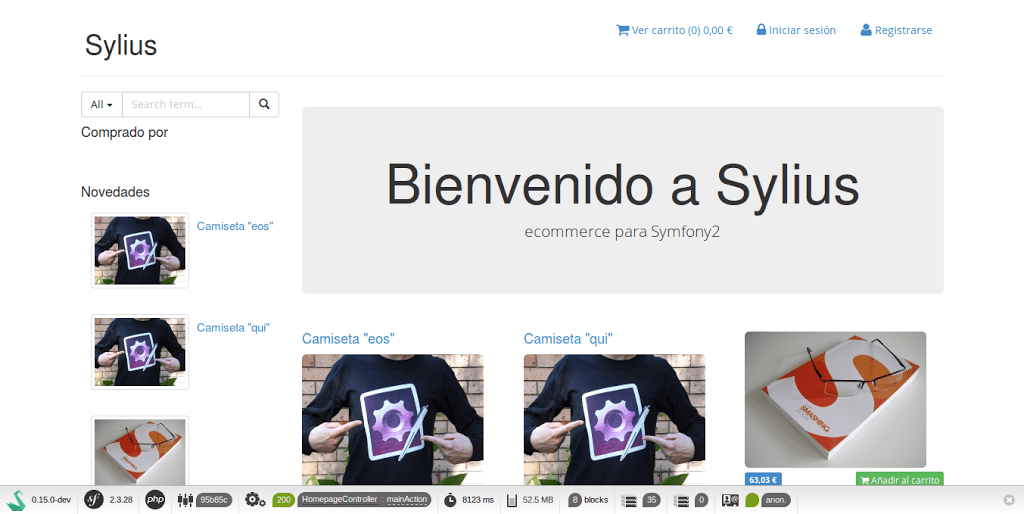
Brutal el proyecto que están desarrollando en Sylius. Navegando y navegando por proyectos para hacer tiendas online. Viendo las principales opciones del mercado: Magento, Prestashop y WordPress con WooCommerce. Me planteaba la opción de cómo sería desarrollar una tienda completa en Symfony. Integrar pasarelas de pago, métodos de envío, ordenando todo los productos por categorías, valores, atributos de los productos.. es un trabajazo. Pero por otro lado no quería prescindir de la flexibilidad y agilidad que nos da un buen framework PHP, en este caso el gran Symfony.
Aterrizaje
Todas estas búsquedas me llevaron a encontrar Sylius. Lo que hasta ahora es el proyecto de tienda online basado en Symfony que me ha parecido más interesante. A fecha en que escribo está en fase de desarrollo aunque hay quien ya lo está utilizando.
Se trata de un proyecto Open Source, licenciado bajo la MIT license. Esto nos permite usar Sylius para cualquier proyecto, libremente sin coste de compra ninguno. Lo único que no se pude hacer es decir que Sylius lo hemos hecho nosotros, como es lógico. Se puede adaptar, modificar, ampliar, etc.. Cualquier cosa se puede hacer porque lo que tenemos entre manos es un proyecto Symfony.
Diferenciación
La principal diferenciación es que para modificarlo no tienes que leerte una ingente cantidad de documentación. Cuando estás desarrollando algo para algún CMS como WordPress, Magento, Joomla.. debes tener siempre a mano su documentación. Acabas especializándote y luego no te puedes salir de dicha plataforma. Por otro lado, el que mucho abarca poco aprieta, no te puedes espcializar mucho en un CMS en concreto. Si lo haces, que luego no te saquen de ahí porque cuando te llevan a otro CMS es otro mundo.
Al ser una plataforma 100% en Symfony, todo sigue el esquema general. Las plantillas están donde deben de estar, igual los controladores, las entidades de las bases de datos. La estructura de directorios es la misma que la de cualquier proyecto Symfony. Las nuevas librerías se añaden igual que cualquier proyecto Symfony. Todo está en su sitio. Esto agiliza mucho la adaptación y ampliación de funcionalidades. No necesitas sumergirte en un mar de documentación específica del CMS en cuestión.
Características
Por su propia naturaleza, se trata de un programa muy potente, rápido, flexible, adaptable y escalable a más no poder. Es como si se tratara de un desarrollo de una tienda 100% artesanal, pero donde estará casi todo listo para usar.
Esta siendo traducido a varios idiomas, con zona frontal, zona de administración. Tendremos productos, el clásico carro de la compra, productos organizados por categorías y atributos, formas de pago, métodos de envío, gestión de mensajes de clientes, páginas estáticas, además de muchas otras configuraciones. Incluso se prevee la inclusión de una API para interconectar el sistema Sylius con otros sistemas.
Resumiendo
¡Toda una joya de la informática! A mi me parece un gran proyecto. Que está siendo organizado empresarialmente desde Lakion.com. Una empresa que preveo que ofrecerá todo tipo de servicios alrededor del proyecto. De igual forma que hacen la mayoría de proyectos Open Source.
Resumiendo, tenemos un gran proyecto. Pretende revolucionar el mundo de los CMS de tiendas online. Está siendo una revolución en el mundo de la programación a medida. Y seguro que lo va a ser también en el mundo de los CMSs cuando alcance su madurez para que cualquier no-programador lo use.
Hola de nuevo, ya estoy trasteando con un nuevo editor de código fuente que hace poco ya alcanzó la versión de producción 1 y está en el momento en que escribo en la versión 1.0.7. Estoy hablando del Atom Editor, un editor de códigos fuentes ligero, rápido, con todo tipo de plugins.. como dicen en su web: un editor hackeable del siglo 21. Es sencillo a más no poder, pero a la vez se puede mejorar instalando paquetes y pieles, que lo convierten en una potente herramienta.
Como punto de entrada me sorprendió no recuerdo donde que leí que estaba hecho en HTML, CSS y Javascript. Ya sólo esto me sorprendió así que hace un par de meses decidí instalarlo y probarlo. No probé demasiado bien, pero ahora que ya ha alcanzado cierta madurez lo he probado bien durante una semana y estos son los resultados.
Características
Al estilo Sublime Text o tipo Eclipse con un estilo ‘dark’ resulta agradable ya la primera impresión. Tus ojos descansan con colores suaves mientras lees los códigos. Como es un proyectos de Github, trae integrada la detección de cambios Git del repositorio que estés viendo. Rápido como él sólo, arranca bien, abre las ventanas rápido con un ‘click’ cada archivo. Explorador de archivos integrado. Opción de abrir un directorio, un sólo archivo, varios proyectos en la misma ventana, o varias ventanas con distintos archivos o proyectos. Puedes abrir todo tipo de archivos de texto. También imágenes, que en mi caso el poder ver las imágenes en el propio editor se agradece. Se pueden dividir las ventanas en paneles para poner en cada uno un archivo según necesitemos.
Cuando empecemos a instalar paquetes para nuestras necesidades es cuando nos daremos cuenta de lo potente que es. La comunidad está desarrollando gran cantidad de ellos para todo o casi todo lo que he buscado. En mi caso, el hacer webs usando un editor de código que en sí mismo está hecho como una web me impresiona. Le he puesto el autocompletado para los lenguajes que uso, el resaltador de error de sintáxis, el famoso minimapa y otros plugins.
Lo tenemos disponible para Linux, Mac, FreeBSD y Windows.
Cuando digo packages, aquí es lo mismo que los plugins de WordPress, los complementos de Firefox, o las aplicaciones de un sistema operativo. Pues aquí se llaman packages, que son lo que completan con infinidad de funcionalidades este fenómeno editor. En mi caso, estoy probando y me quedo con los siguientes:
atom-autocomplete-php: para autocompletar rápidamente en proyectos basados en Composer.
atom-beautify: pone bonito el código identándolo, poniendo espacios o quitándolos donde debe, etc. Si tienes instalado php-cs-fixer te formatea el código según el estándar PSR.
autocomplete-plus: es básico para que otros paquetes de autocompletado funcionen.
php-twig: compatibilidad con Twig, muestra mensajes emergentes con sugerencias también.
php-getters-setters: como su nombre indica, genera los getters y setters de una clase PHP.
minimap: este me gusta mucho porque te visualiza una ventana lateral con todo el código fuente en miniatura con el que te puedes mover por un archivo.
linter y linter-php: analiza el código mostrando menús emergentes, errores sintácticos, etc. Muy bueno, imprescindible.
docblockr: genera comentarios automáticamente según escribes en las cabeceras de clases o funciones.
custom-title: con el que puedes configurar los títulos de la ventana mostrando, por ejemplo, el nombre del proyecto, la rama y la ruta completa al archivo. Muy configurable y útil para saber donde estás.
git-plus: para hacer tareas de Git dentro del editor. En mi caso, en Linux, pulsando Ctrl+Shift+H se me despliegan los comandos disponibles.
Veo brutalmente buenos estos packages, ya cada uno que busque los suyos. Tenemos disponibles 2602 en la fecha en que escribo esto según pone en:
https://atom.io/packages
¡Hay que probarlo que es una joya de la informática! Un saludo.
LibreOffice es una suite ofimática, es decir, para trabajos relacionados con la oficina como pueden ser documentos de texto, hojas de cálculo, presentaciones, incluso tiene para bases de datos. Toda una joya de la informática les traigo hoy con éste programa. Ya lo he mencionado anteriormente en otro post pero no por ello deja de tener mucha importancia.
La competencia
Pues bien, comparando con otras soluciones de pago como pueden ser Microsoft Office o los Google Docs que tenemos gratis disponibles en dispositivos Android. Tenemos ahora que LibreOffice va siendo cada vez más una gran solución que casi no tiene nada que envidiar al resto.
Vengo leyendo desde hace un tiempo que tienen planeado la edición de documentos online. Es decir, se instalará LibreOffice en un servidor desde el que se servirán los archivos. ¿Os suena?, al estilo que los documentos de Drive o el Office Online de Microsoft.
Entre las nuevas mejoras trae una interfaz renovada, que desde se separó el desarrollo del estancado OpenOffice, han ido queriendo diferenciarse cada vez más y más. También informan en su web que tenemos mejoras sustanciales en el funcionamiento de las hojas de cálculo, filtros, mayor velocidad, etc.
Todo apunta a una serie de características de la versión 4 que se han ido mejorando cada vez más y ahora espero que estemos en un punto de inflexión en donde se apunte más a la nube, al trabajo en red con ficheros de LibreOffice.
Otro punto importante son las mejoras de las aplicaciones para móviles. Son conscientes que los dispositivos móviles y tablets van a tener una importante presencia. Pero no van a descartar a los ordenadores, porque una buena pantalla junto con ratón y teclado no dejarán de ser más productivos a la larga para las tareas ofimáticas.
Puede ser algo trivial, pero es el punto de partida para iniciar la internacionalización de una web. Me refiero a la llegada del usuario, recogida del código de idioma y región del navegador, se comprueban los idiomas disponibles y posteriormente se le redirige a la página de su idioma correspondiente.
Es mucho más sencillo que lo que puede parecer a priori, pero claro está, hay que tener claras un par de cosas que si no después se complica.
El usuario llega a la web
En este punto, tenemos un usuario que llega a la web. Ahora es el momento de elegir el idioma en que le vamos a mostrar la página web al usuario. Que podemos hacerlo de dos formas diferentes: eligiendo el idioma por defecto o con el idioma que nos sugiera el navegador.
Vamos a empezar con un ejemplo de controlador que recibe la visita inicial del usuario:
<?php namespace FrontBundleController;
use SymfonyBundleFrameworkBundleControllerController; use SensioBundleFrameworkExtraBundleConfigurationRoute; use SensioBundleFrameworkExtraBundleConfigurationTemplate; use SymfonyComponentHttpFoundationRequest; /* * Controlador de ejemplo para empezar a traducir una web. * Sólo tiene las dos rutas necesarias para empezar la navegación traducida * Se necesita de la entidad Idioma para tener los idiomas disponibles. */ class DefaultController extends Controller { /** * Esta ruta es la página de inicio. Simplemente recibe al visitante * busca entre los idiomas publicados y le redirige a la ruta siguiente * poniendo el código del idioma en la URL. * * @Route («/», name=»iniciototal») */ public function inicioTotalAction(Request $request) { $manager = $this->getDoctrine()->getManager();
// Creamos el array de idiomas disponibles que se obtienen de la // entidad Backbundle:Idioma, aquí lo que hacemos es recuperar de la // BD los idiomas publicados guardando en un array los códigos de idioma. $idiomas = $manager->getRepository(‘BackBundle:Idioma’)->findBy(array( ‘publicado’ => true )); $idiomasarray = array(); foreach ($idiomas as $idioma) { $idiomasarray[] = $idioma->getCodigo(); }
// Consulta los lenguajes preferidos del navegador, comprueba // los que tenemos disponibles disponibles devolviendo el primero // que tenemos disponible de los preferidos por el navegador. $codigoLocale = $request->getPreferredLanguage($idiomasarray);
// Redirigimos la visita a la ruta de abajo poniéndole el código // del idioma. return $this->redirect($this->generateUrl(‘inicio’, array( ‘_locale’ => $codigoLocale ))); } /** * En esta ruta ya tenemos un código de idioma establecido, * podemos hacer a partir de aquí todo. El resto de rutas de la aplicación * deben tener la ruta de la forma «/{_locale}/resto/de/la/ruta» * para continuar navegando en el idioma actual. * * @Route («/{_locale}/», name=»inicio») * @Template */ public function inicioAction($_locale) { $manager = $this->getDoctrine()->getManager(); // Aquí tenemos ya el código de idioma en la variable especial $_locale // con esto ya podemos consultar la BD con el idioma que tenemos en curso // mostrándole al usuario todo traducido o lo que sea que necesitemos hacer.
return array(); } }
A partir de aquí ya tendremos la visita con el idioma. La variable _locale es una variable especial. Se puede consultar en las plantillas Twig poniendo en la plantilla:
{{ app.request.locale }}
La variable _locale es especial porque se establece a partir del momento en que la establecemos nosotros. Se nos puede ocurrir obtener el _locale de la aplicación con la instrucción siguiente en el controlador:
$this->getRequest()->getLocale();
Si hacemos esto en el controlador, en la ruta «iniciototal», no obtendremos el _locale del navegador, si no que obtendremos el _locale puesto en el fichero de parámetros de configuración parameters.yml. A mi me ha pasado y lleva a confusión. Podemos usar ésta última instrucción y tendremos el código de idioma actual si lo hemos establecido recibiendo el _locale en la ruta poniendo siempre al principio del resto de las rutas el _locale. Como indico en el comentario del código, usando rutas de la forma «/{_locale}/resto/de/la/ruta». Es decir, tendremos que recibir la variable {_locale} en todas las rutas para poder usar en el controlador:
$this->getRequest()->getLocale();
.. y que nos devuelva correctamente el idioma. Si lo que queremos es ver el _locale que nos pide el navegador podemos ejecutar lo siguiente:
En estos días he estado haciendo una copia de seguridad de una base de datos compatible con MySQL. En concreto de MariaDB, un ‘replace’ que funciona muy pero que muy bien. Para éste ejemplo he usado un servidor Linux, supongo que en otros sistemas operativos también tendremos disponibles estos comandos.
MariaDB es un fork de la conocida base de datos MySQL que ha seguido más y más desarrollándose e incorporando más y más funcionalidades.
Vamos al grano, es sencillo exportar a un fichero SQL desde línea de comandos con un comando como el siguiente: $ mysqldump nombreBaseDeDatos -uuser -ppassword > nombreFichero.sql
Lo que hay después de -u es un nombre de usuario, después de -p la contraseña, debe ser un usuario y contraseña válidos y que tengan permiso de acceso a toda la base de datos.
Si queremos hacer pruebas antes de guardar a un fichero el contenido podemos omitir lo último del comando para ver lo que hay en la BD.
$ mysqldump nombreBaseDeDatos -uuser -ppassword
A continuación, si queremos importar el fichero SQL ejecutamos lo siguiente en línea de comandos:
$ mysql nombreBaseDeDatos -uuser -ppassword < nombreFichero.sql
Hace poco escribí, desde el punto de vista de la programación, sobre el proyecto #Syncthing. Viendo y viendo alternativas a #Dropbox, #Google #Drive, #One #Drive, etc. Llegué a encontrar #BitSync, #SeaFile, #OwnCloud. Muy interesantes todos, pero en particular me parece especialmente interesante Syncthing por eso estoy escribiéndoles este post. Vamos a echarle un vistazo..
Se trata de un programa, o exactamente, un proyecto que incluye varios programas. Con los cuales podemos conectar varios ordenadores y sincronizar archivos entre ellos.
Qué es
Técnicamente es un programa cliente-servidor de sincronización de ficheros. Lo novedoso es que te hace independiente de cualquier empresa intermedia y puedes configurarlo de forma que no haya nadie que pueda saber nada de tus archivos. La información puede transmitirse exclusivamente entre tus ordenadores.
El servidor
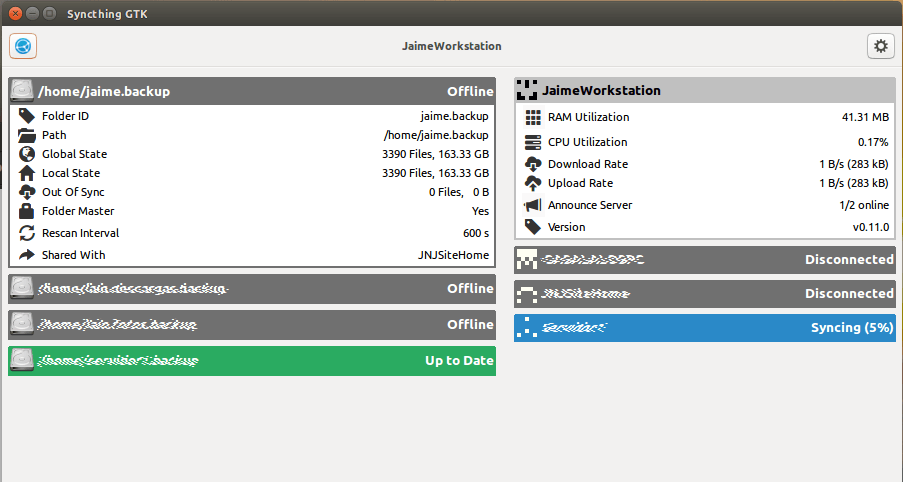
En la fecha en que les escribo tenemos disponible la versión 0.11.3, que se distribuye independientemente de las interfaces disponibles. Se trata de un servicio para el sistema operativo que proporciona una interfaz web y una API rest para poder conectar desde otros programas y manejarlo.
El servidor de descubrimiento global
Lo único externo a nosotros que de momento están proporcionando los desarrolladores es dicho servidor de descubrimiento.
¿Porqué es necesario? Piensa en si tienes un ordenador en tu casa y otro en el trabajo, ¿cómo se encuentran? Fácilmente, cada uno siempre le dice al servidor de descubrimiento donde está. Así cuando tengan que sincronizar los archivos se conectan directamente el uno al otro.
Dicho servidor de descubrimiento también lo tenemos disponible.
Interfaz
A fecha de hoy he leído que tenemos para Mac, Windows, Linux, FreeBSD y Solaris. Leo que hay un proyecto de interfaz multiplataforma con GTK pero no lo he probado nada más que en Linux, y funciona muy bien. Es el de la foto.
La interfaz te puede poner un bonito icono en la barra de tareas y encargarse de arrancar o de instalar el servidor.
Terminando
Para resumir, de todas las alternativas que he probado, para estar tranquilo de que las copias de los archivos se están haciendo correctamente, me quedo con Syncthing 🙂
Se me olvidaba comentar que es un proyecto Open Source, por eso que da gusto compartirlo y si quieres echar una mano siempre puedes curiosear un poco más.
Resulta que si tienes un servidor Linux, ya sea dedicado o virtual. Puede ser que no tengas una copia de seguridad automatizada de tus principales archivos. Los proveedores de servidores suelen ofrecer este servicio aparte cuando contratas un servidor. También puede ser que quieras automatizarlo en un ordenador local de ésta forma. Aquí les dejo un script simplificado por si les sirve de ayuda:
### FICHERO PARA AUTOMATIZAR LA COPIA DE SEGURIDAD ### DE TODOS LOS DATOS DEL SERVIDOR FECHA=$(date +%Y%m%d%H%M%S) # COPIA A FICHERO DE LA BD mysqldump nombreBD -uusuario -ppassword > backups/nombreBD.temp.sql tar -cvzf backups/nombreBD.${FECHA}.tar.gz backups/nombreBD.temp.sql rm backups/nombreBD.temp.sql # BD otras bds.. # copia incremental en el directorio de copia # ojo! la primera vez hay que poner ‘full’ en vez de ‘incremental’ para preparar la primera copia duplicity incremental –encrypt-key «password» –volsize 100 –no-encryption /home/ubuntu file:///home/ubuntu.backup/ –exclude /home/ubuntu/undirectoriodecache/ # borra historial de archivos antiguos duplicity remove-older-than 60D file:///home/ubuntu.backup/ # limpia copias incompletas o mal realizadas duplicity –no-encryption cleanup file:///home/ubuntu.backup/
Suponiendo que nuestro usuario se llama ‘ubuntu’ y estamos en el directorio del usuario (/home/ubuntu/). Este script se puede guardar en un fichero, por ejemplo: copiarTodo.sh Le damos permiso de ejecución con:
$ chmod +x copiarTodo.sh
Así podremos probarlo antes de programar su ejecución periódica. Ejecutamos: $ ./copiarTodo.sh
..y vemos los resultados, es decir, vemos el directorio de salida de los ficheros generados:
/home/ubuntu/backups/ es el directorio donde se copian los datos de la base de datos compatible con MySQL.
/home/ubuntu.backup/ es el directorio de salida de Duplicity.
Para terminar falta programar la ejecución de dicho script. Para ello ejecutamos lo siguiente:
$ crontab -e
…y añadimos lo siguiente para una ejecución semanal por ejemplo el domingo a las tres y cuarto de la madrugada:
15 3 * * 0 ~/copiarTodo.sh > ~/copiarTodo.log
mysqldump
A saber, por si acaso no lo conocen, este es el comando de Linux que desde terminal permite extraer de una base de datos compatible con MySQL todos los datos y guardarlos en un fichero.
duplicity
Este programa es el que se utilizar para hacer copias de seguridad en Ubuntu. Por debajo del sistema de copias que viene instalado llamado Deja-dup, tenemos dicho Duplicity. Como es una aplicación de línea de comandos lo que tenemos en el entorno de escritorio es una interfaz de usuario a dicho programa.
Duplicity permite hacer copias incrementales. Es decir, después de una primera copia total de todos los archivos, permite en las siguientes sólo copiar los ficheros en los que ha habido cambios. Además las copias se empaquetan en ficheros de cierto tamaño, cifrados y protegidos con contraseña. Incluso se pueden enviar automáticamente a un servidor de ficheros FTP, por ejemplo.
Me remito a la documentación oficial para más información.
Navegando, navegando me he topado con este brillante programa. Se trata de una interfaz que coordina todo el mantenimiento de programas para Windows, y poder ejecutarlos en Linux.
Muchos de ellos te los descarga y te acompaña en la instalación. Tenemos un buen directorio donde tenemos las aplicaciones compatibles y probadas. Por si no era bastante con la avalancha de videojuegos que están llegando a Linux en los últimos tiempos, también tenemos disponible muchos de los de Windows, plataforma por excelencia para los jugones.
No lo he explicado, Wine es una capa de software que hace posible la ejecución de programas nativos de Windows en Linux.
Se acerca el fin de semana, si tienes Linux, tienes aquí una joya de la informática para probar 😉
Es bien sencillo. Abrimos un terminal si estamos en una estación de trabajo, o nos conectamos al servidor si es así. Entonces ya tenemos acceso.
En Ubuntu funciona de ésta manera, no creo que varíe mucho de una distribución de Linux a otra. Ejecutamos:
$ crontab -e
Entonces veremos unas explicaciones en inglés donde detallan todo. Tendremos que poner una línea nueva para cada tarea. Por ejemplo nos puede quedar algo tal que así:
# Edit this file to introduce tasks to be run by cron. # # Each task to run has to be defined through a single line # indicating with different fields when the task will be run # and what command to run for the task # # To define the time you can provide concrete values for # minute (m), hour (h), day of month (dom), month (mon), # and day of week (dow) or use ‘*’ in these fields (for ‘any’).# # Notice that tasks will be started based on the cron’s system # daemon’s notion of time and timezones. # # Output of the crontab jobs (including errors) is sent through # email to the user the crontab file belongs to (unless redirected). # # For example, you can run a backup of all your user accounts # at 5 a.m every week with: # 0 5 * * 1 tar -zcf /var/backups/home.tgz /home/ # # For more information see the manual pages of crontab(5) and cron(8) # # m h dom mon dow command 0 4 * * sun /home/ubuntu/duplicity.backup.sh
Aquí puedes ver todas las explicaciones, y al final una simple linea que es mi tarea. Se ejecuta en el minuto 0 a la hora 4, para todos los días del mes, para todos los meses, sólo los domingos. Esto mismo en inglés lo explica en los comentarios en inglés.
Es importante saber que si ejecutamos ‘crontab -e’ como usuario entonces editamos las tareas del usuario que tengamos. Podemos hacer lo mismo para el superusuario. Si nos interesara ejecutaríamos ‘sudo crontab -e’.
Los comandos se ejecutan desde el directorio del usuario. Ten cuidado con ésto porque si lees o escribes ficheros ten en cuenta de usar rutas absolutas o rutas relativas desde el directorio de trabajo del usuario que ejecutará la tarea. Sino no funcionará.
Como curiosidad, Duplicity es una gran herramienta para hacer copias de seguridad incrementales, cifradas, comprimidas y otras tantas características que tiene, todo desde línea de comandos. Ubuntu en su sistema de copias de seguridad, usa Duplicity por debajo. Si quieres échale un vistazo que merece la pena 😉