Una de las tareas de servidor más comunes, o lo debería ser, es la copia de seguridad de los archivos. Si no queremos tener más problemas que los necesarios nos conviene tener una copia. Así que aquí estoy de nuevo escribiendo sobre Virtualmin, este gran proyecto Open Source que nos brinda una brillante interfaz de usuario web. Traigo un pequeño HOWTO para programar las copias de seguridad con este software.
Continuar leyendo..Cómo hacer un píxel de conversión
2017-03-24 - Categorías: General

Imagina que contratas a una persona para que te haga publicidad en varias webs. Llegas a un acuerdo de darle un monto por cada visita que llega a través de la publicidad que te hace. O un porcentaje por venta que llega de su web. Pero ¿cómo saber si este comprador que ha llegado a tu web viene de haber visto la publicidad de esta persona que te publicita?
Esto se puede hacer con los llamados píxeles de conversión. Simple y llanamente son páginas web que estan en el servidor de tu negocio que se dedican a enviar cookies, incrustándose en las páginas que te hacen publicidad mediante iframes o llamadas de Javascript. Entonces, si alguno de dichos visitantes llega a tu negocio con una de esas cookies, ya sabes que ha visitado la web que te está haciendo publicidad y le darás las gracias con razón 😉
Continuar leyendo..
Una de las alternativas de almacenamiento en la nube más prometedoras es Mega. Proviene de la antigua Megaupload, de la mano de Kit Dotcom, fundador de Megaupload. Lo pusieron en marcha Kim junto a su equipo de trabajo, parece que como respuesta al cierre y confiscado de Megaupload debido a la piratería. Mega puede parecer algo novedoso, sin embargo, no es más que el mismo sistema de almacenamiento en la nube de archivos pero mucho más elaborado que el anterior. Salió al mercado hace ya cuatro años, en el 2013. Fue tanta la expectativa que hubo millones de usuarios que se registraron en muy poco tiempo hasta colapsar sus servidores. A día de hoy Kim Dotcom se ha desvinculado del proyecto, y navegando un poco puedo leer reseñas que hablan que hay alrededor de 50 millones de usuarios registrados en Mega.
Sus principales bazas en el mercado del almacenamiento en la nube han sido dos: los famosos 50 Gigas gratis, y su esfuerzo por la privacidad de los usuarios.
Continuar leyendo..Igual que en otros lenguajes de programación, aquí en PHP también tenemos disponibles funciones del estándar POSIX para gestionar procesos, obtener información de ellos, hacer colas FIFO, enviar señales, hacer procesos hijos, esperar a que terminen unos para continuar otros, matarlos.. etcétera. Todo esto te dará lo que necesitas para pasar de una programación lineal, paso a paso, a una programación concurrente, paralelizando los procesos.
Esto se usa desde línea de comandos. No recomiendan en absoluto que se active y se use esto sobre servidor web, ya que los servidores web tienen sus propias estrategias de paralelización. Pero si como yo, has estado trabajando desde línea de comandos con este tema. Y has llegado a tareas que tardan mucho tiempo y se lanzan desde línea de comandos. Con esto podrás lanzar en paralelo todas las tareas que necesites, así aprovecharás todos los núcleos del procesador, y terminará antes el proceso completo.
Necesitarás tener activado el módulo PCNTL en PHP. Para saber si ya lo tienes activado ejecuta php -i, si no edita el php.ini para activarlo.. En PHP7 ya me venía activado. Con esto te evitas también la engorrosa instalación de Pthreads recompilando PHP con ZTS, además de la instalación posterior de Pthreads. Simplemente usando el mencionado PCNTL..
Continuar leyendo..Prestashop 1.7: las apariencias engañan, muchos cambios donde no se ve
2017-01-23 - Categorías: General / Prestashop
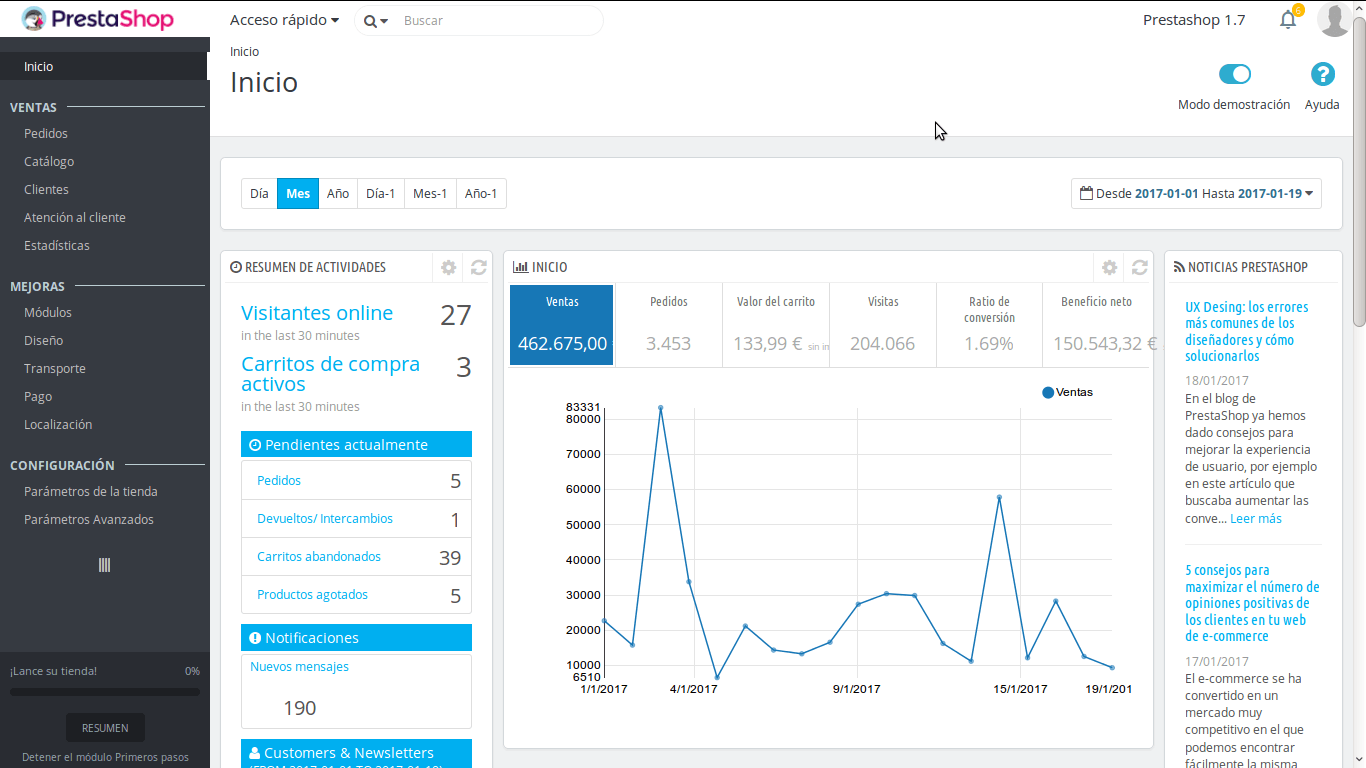
El 7 de noviembre de 2016 se publicó la nueva versión 1.7 de Prestashop. Esta versión trae un remake del 100% del core, reescrito con Symfony. Cuando leí sobre esto, empezó a intrigarme más y más. Quería ver cómo iba este proyecto. Pasó por mis manos un proyecto que funciona en Prestashop 1.6, ¡qué lástima!, no íbamos a actualizarlo. Pero ahora sí, tenemos entre manos un nuevo proyecto, y tenemos que estimar a ver si lo montamos sobre Prestashop 1.7. Así que manos a la obra..
Continuar leyendo..PHP: bajar ficheros con HTTP, leer y escribir a disco, y subir ficheros a FTP
2017-01-09 - Categorías: PHP

Jeje, llevo unos cuantos días que no escribo en mi cuaderno de bitácora. No sé si alguien realmente me sigue aquí. Pero como vengo diciendo, no hay que perder las buenas costumbres 😉 En estos días de tanto ajetreo por la Navidad, más algunos proyectos y deberes pendientes de fin de año, que no he tenido casi tiempo..
En uno de los proyectos he tenido que andar bajando ficheros de feeds de datos, cruzando los datos y subiendo los resultados. Así que he pensado que un par de HOWTOs sobre esto a alguien le pueden venir bien. Y si has llegado aquí buscando como hacer cosas de estas, más sencillo no se me ha ocurrido cómo explicarlo.
Continuar leyendo..
Estas semanas atrás hemos tenido algunos problemas en algunos WordPress. Recurrentemente, las páginas web daban resultados en blanco. Era raro pues no teníamos registros de bloqueo. No había saltado el cortafuegos por poner mal las contraseñas. De repente, no teníamos servicio, otra web.. ahora el servicio de correo.. Un compañero de trabajo, luego otro.. Con cuentagotas iban reportando las incidencias. Tirando del hilo, tirando del hilo.. llegamos a la conclusión de que ¡todo en el servidor estaba fallando! ¡no puede ser!
Se trata de un servidor administrado en el que no tenemos que hacer ninguna gestión. El sistema operativo se mantiene actualizado automáticamente por la empresa que nos aloja. Siempre ha ido todo perfecto. El cambio siempre ha sido a mejor de todas las webs aquí alojadas.. Visto esto, y sabiendo que un WordPress sin actualizar puede ser origen de una ingente cantidad de problemas, me pongo manos a la obra. Reviso las actualizaciones de toooodos los WordPress que hay en este servidor. Uno a uno, actualizándolos todos manualmente. Me encontré con algunas actualizaciones que no se habían hecho, incluso teníamos un WordPress a medio actualizar que se había quedado enganchado. Varios proyectos heredados junto con otros nuevos. En fin, tareas rutinarias que hacer para poner todo al día..
Ahora mismo ya está todo arreglado y funcionando perfectamente. Cierto es que hemos tenido algunos problemas de rendimiento a nivel de sistema operativo. Pero por otro lado teníamos algunos WordPress que actualizar y poner al día. Así que, ahora que ya volvió el agua al río, y se arrojó luz sobre el origen de los problemas.. aquí estoy con algo de material nuevo.
Continuar leyendo..HeidiSQL ¡menuda joya de la informática!
2014-11-12 - Categorías: General
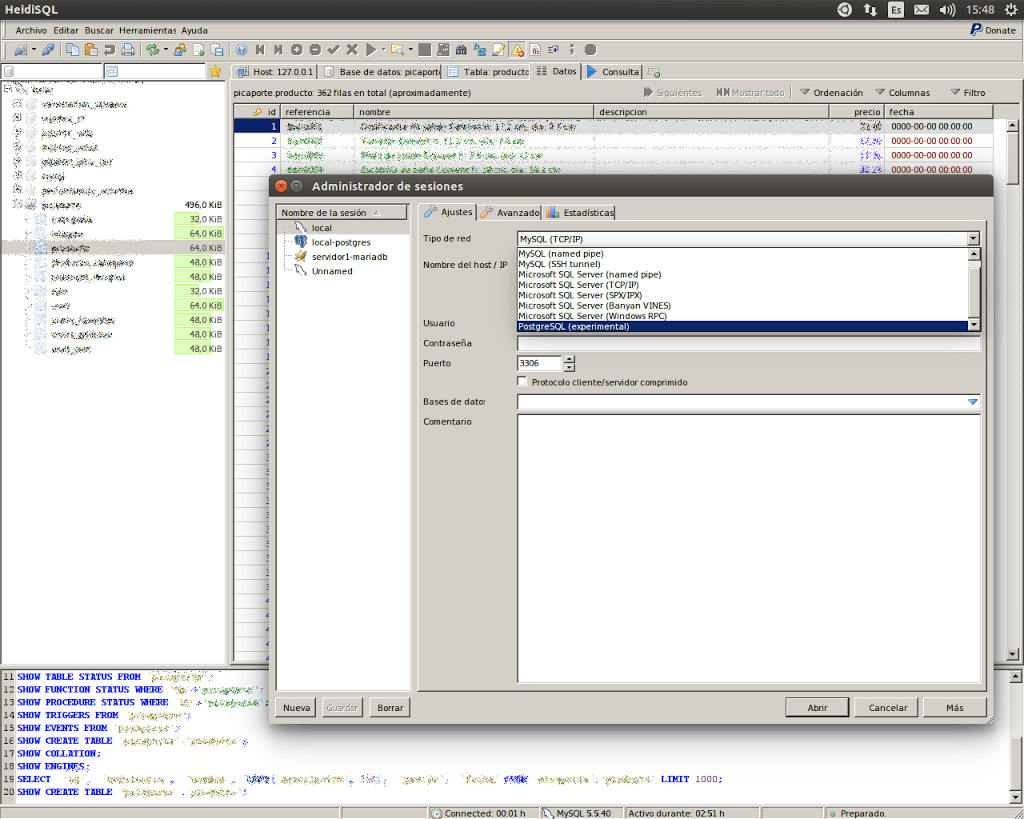
¡Uau! Me he quedado boquiabierto al curiosear el proyecto que están montando con HeidiSQL. Es uno de ésto proyectos que al verlo me lo descargué sin pensármelo. He estado probándolo para conectar a bases de datos MySQL y MariaDB. Cuando me he decidido a curiosearlo un poco más a fondo, no he podido aguantarme, y aquí estoy compartiéndolo para todos los que entran a leerme.
Características
HeidiSQL es un programa gestor de bases de datos. Es decir, es un cliente que se conectar a servidores de bases de datos. Nos permite hacer practicamente de todo, por lo menos con las bases de datos MySQL y MariaDB.
Podemos conectar a también a bases de datos de Microsoft SQL Server y en las últimas versiones están experimentando con la conexión al gran Postgresql. Éste proyecto promete mucho, y seguro que seguiremos leyendo más sobre él. Ahora incluso más que se lanza a añadir Postgresql como la siguiente base de datos compatible.
Instalar Bower en Ubuntu
2014-11-02 - Categorías: General
¡Buenos días!
Estoy escribiendo poco últimamente sobre programación. No me he olvidado del blog, es que gracias a Dios estoy teniendo menos tiempo. No está la cosa para echar cohetes acá en Spain pero voy a intentar apretar y no abandonar en las buenas costumbres, como por ejemplo, escribir en un blog 😉
Para instalar Bower tuve que navegar para encontrar dispersa alguna información, así que aquí les dejo todo junto en un post.
Qué es
Bower es una excelente herramienta para automatizar la gestión de tus librerías. Está creada para gestionar los fuentes de la parte front-end. Es decir, Bower nos descarga y actualiza las librerías de entorno cliente: CSS, HTML y Javascript que necesitemos. Puede ser por ejemplo las librerías de Bootstrap o jQuery.
Instalar
Necesitaremos tener instalado:
- Git
- npm
- nodejs
La web oficial es: http://bower.io/
Los comandos para instalar son los siguientes:
$ sudo apt-get update
$ sudo apt-get install git
$ sudo apt-get install npm
$ sudo apt-get install nodejs
$ sudo npm install -g bower
Llegados a éste punto si ejecutamos ‘bower update’ nos saldrá un error porque no encuentra ‘node’. Ésto pasa porque el ejecutable en Ubuntu no es node es nodejs y no lo encuentra. Así que creamos un enlace simbólico y asunto solucionado.
$ sudo ln -s /usr/bin/nodejs /usr/bin/node
Ejecutar
Ya teniendolo instalado nos falta una configuración sencilla en dos ficheros. Primero un bower.json donde elegimos qué librerías necesitamos:
{
«name»: «Nombre del proyecto»,
«version»: «1.0.0»,
«dependencies»: {
«jquery»: «latest»,
«jquery-ui»: «latest»,
«bootstrap» : «latest»,
«font-awesome»: «latest»
}
}
Si ponemos en la versión de cada dependencia latest siempre nos descargará o actualizará a la última versión de la librería. Segundo para configurar en qué directorio queremos todo podemos crear un fichero .bowerrc
{
«directory»: «lib»,
«json»: «bower.json»,
«searchpath»: [
«https://bower.herokuapp.com»
]
}
Ahora todas las librerías las tendremos bajo el directorio /lib cuando ejecutemos lo siguiente:
$ bower update
Para terminar de incluir todas éstas librerías en un fichero HTML y usarlas podemos poner un HEAD parecido al siguiente:
<head>
<title>Título de la web</title>
<meta charset=»utf-8″>
<meta name=»viewport» content=»width=device-width, initial-scale=1.0″>
<link rel=»stylesheet» href=»lib/bootstrap/dist/css/bootstrap.min.css» type=»text/css»>
<link rel=»stylesheet» href=»lib/font-awesome/css/font-awesome.min.css» type=»text/css»>
<script src=»lib/jquery/dist/jquery.min.js»></script>
<script src=»lib/jquery-ui/jquery-ui.min.js»></script>
<script src=»lib/bootstrap/dist/js/bootstrap.min.js»></script>
<script src=»main.js»></script>
<link rel=»stylesheet» href=»estilo.css» type=»text/css»>
</head>
Ya podemos empezar a maquetar y programar usando jQuery, jQuery-UI, Bootstrap y las Fuentes Asombrosas. No hemos tenido que ir web a web descargando todas las librerías una a una. Además si ahora ejecutas en cualquier momento ‘bower update’ se te actualizarán las librerías a la última versión.
Si has llegado hasta aquí espero que te estén sirviendo de ayuda.
Un saludo 🙂
LibreOffice, el office nuestro de cada día
2014-11-01 - Categorías: General
¡Hola de nuevo!
¿Cómo podía dejarme ésta suite ofimática que todo ordenador debería de llevar? Tienes las utilidades básicas que en la oficina o en casa todos necesitamos: editor de textos, hojas de cálculo, presentaciones, dibujos, e incluso un potente gestor de bases de datos.
Generalmente me dedico a usar el editor de textos y hojas de cálculo. Pero para escribirles éste post me he puesto a curiosear la suite completa a ver qué tal funciona.
Una primera aproximación
Veo que en mi Linux Ubuntu no tengo instalado LibreOffice Base. Es el gestor de bases de datos que tenemos disponible. Me ha parecido muy pero que muy interesante. Así que lanzo mi Centro de software de Ubuntu y me instalo todos los programas de LibreOffice. En su página oficial lo pueden descargar:
A simple vista tenemos una serie de formatos para los documentos totalmente abierta. Es decir, tus archivos de LibreOffice se guardarán en formatos abiertos que cualquier otro programa podrá abrir si es que es compatible. No hay trabas para otros a la hora de hacerse compatibles como solía pasar con muchos formatos patentados, cerrados y sin documentación.
Tenemos la gran mayoría de herramientas que otros programas tienen.
Muchos ya hemos probado los textos, hojas de cálculo y presentaciones. Con los prácticos botones para exportar los documentos a PDF. Todo tipo de herramientas de edición. Etcétera. Así que he hecho unas pruebas con el último elemento que veo que están mejorando con unos resultados bien buenos, el LibreOffice Base.
LibreOffice Base, muy potente
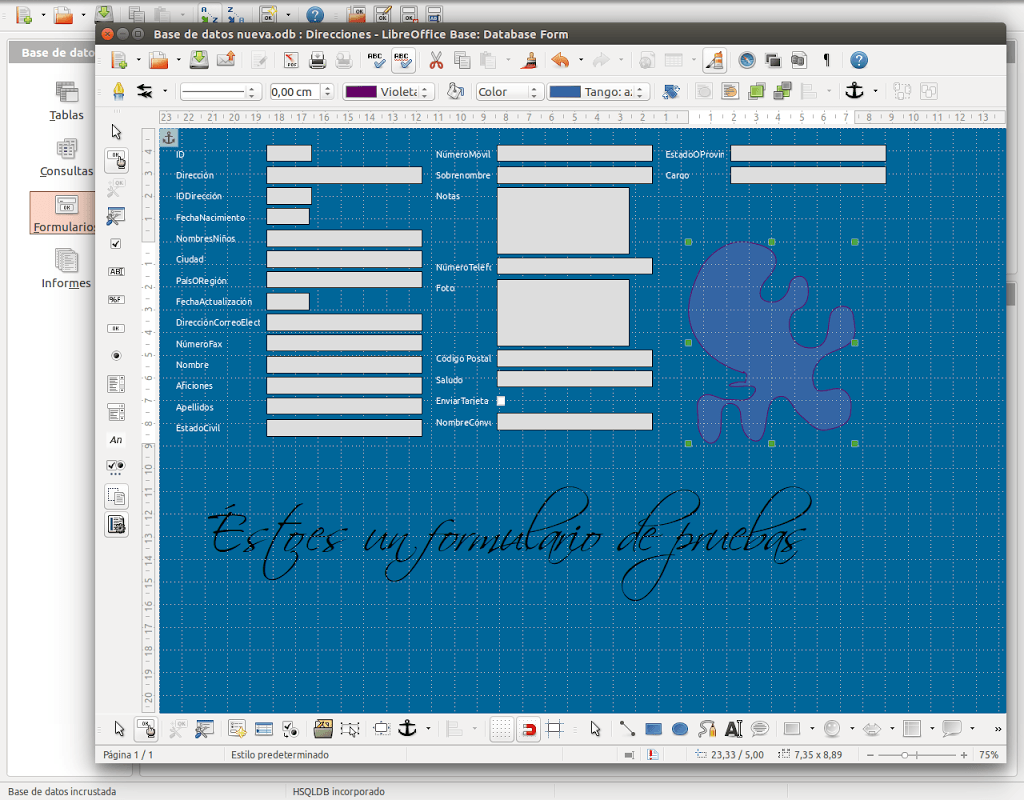
Destaca que permite la conexión con muchas bases de datos como MySQL que tanto se usa en páginas web, con el robusto PostgreSQL.. también incluye un motor de base de datos al que han llamado HSQL.
Tenemos unas plantillas para tablas con las que ir probando. Podemos crear formularios para trabajar con los datos, generar informes de texto, hojas de cálculo.. se integra con el resto de aplicaciones sin atarte a usar su motor de base de datos.
Probando probando he usado una plantilla para trabajar con datos de contactos. Se puede ver en la imagen como en apenas 5 minutos tenemos un formulario listo para usar.
Este proyecto promete mucho, se está gestando algo grande en el mundo de las suites ofimáticas. Y viene del mundo del código libre.
Terminando
También hay otra herramienta como el LibreOffice Math que les dejo para que ustedes prueben 😉
Resumiendo, toda una joya de la informática. De código libre que se puede consultar, se puede colaborar en el proyecto, y por supuesto se puede usar el paquete completo de forma totalmente gratuita y sin restricciones incluso para entornos de trabajo.
Sigo escribiendo desde Linux, hablo de software libre, pero también lo tienen disponible para Windows o Mac.
Un saludo 🙂
Thunderbird: Cuando tienes emails para parar un tren
2014-10-19 - Categorías: General

¡Buenos días! Hace un tiempo que no escribo aquí así que voy a intentar no perder las buenas costumbres dejándoles aquí otro programa que me está haciendo la vida más fácil.
Por cuestiones de trabajo resulta que cada vez más voy acumulando y atendiendo más y más emails. Tengo varias cuentas que hasta hace poco iba recibiendo todos sus emails en una misma cuenta. Una cuenta gratuita con un proveedor de correo electrónico con opción de usarlo gratuitamente hasta cierto punto. Pero llegué al límite de cuentas que podía recibir.
No quería tener que entrar en cada web para consultar los emails y tampoco quería instalarme un programa en local por lo engorroso que puede resultar su mantenimiento pero no encontré otra solución.
Instalación
Me decidí por Thunderbird porque es gratis, de código libre, y primo hermano del navegador Firefox que ya me gustaba.
Enlace de descarga: https://www.mozilla.org/es-ES/thunderbird/?icn=tabz
Porqué
Lo primero es que necesitaba usar muchos emails distintos desde un mismo sitio, asunto solucionado.
Necesitaba poder tener copias de seguridad, solucionado porque con copiar el directorio .thunderbird de tu carpeta personal ya tienes toda la copia de seguridad del programa. No hay que andar con complicados cifrados, claves de instalación ni nada parecido. En caso extremo tenemos unos archivos .msf en ésta carpeta en donde tenemos todos los emails guardados como ficheros de texto puro.
Permite todas las cuentas de correo que quieras sin límite ninguno, ni en almacenamiento ni en tamaño de cada email.
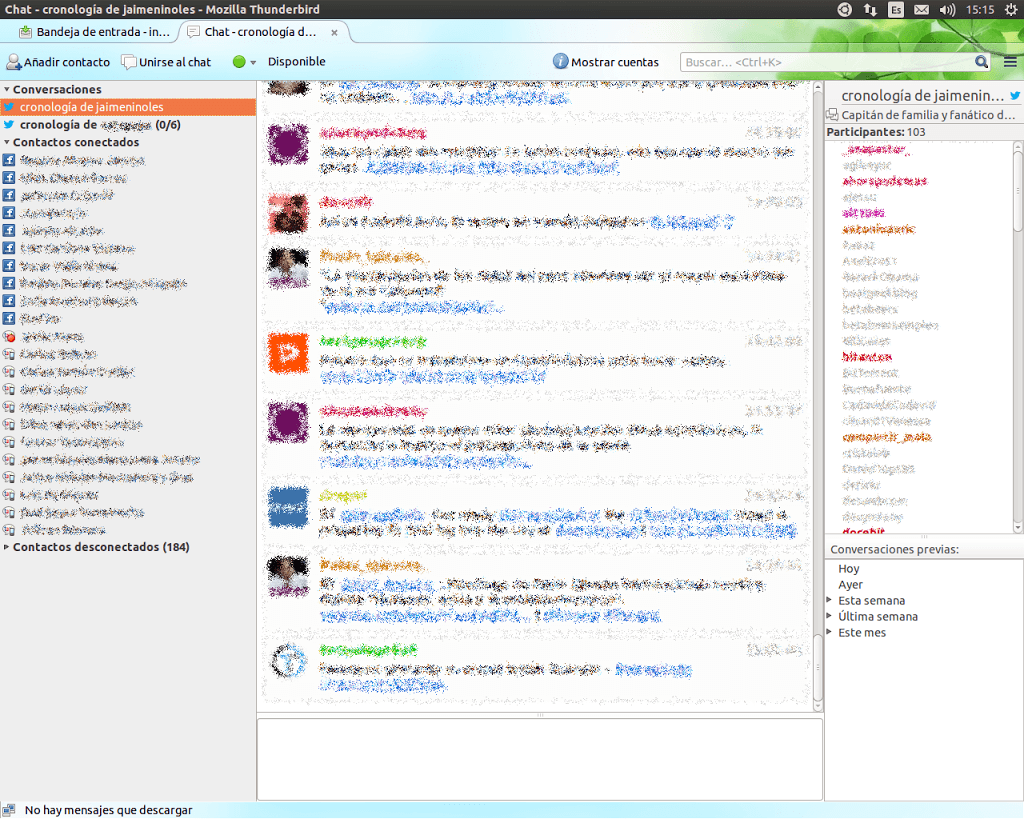
Compatible con SMTP e IMAP, filtros, redirecciones, múltiples carpetas, etc. Todo lo que puedas imaginar que un lector de emails debe tener. Además tiene también libreta de direcciones y un chata donde charlar a través de varias redes sociales. Yo he comprobado que funciona correctamente con GoogleTalk, Facebook y Twitter.
También es compatible con Windows, Mac y Linux. Y lo tenemos disponible en muchos idiomas.
Resumiendo, otra gran herramienta del Open Source para todos. Me ha funcionado de maravilla en todo éste tiempo que lo llevo usando. Lo recomiendo.
Un saludo 🙂
FreeFileSync para tus copias de seguridad locales
2014-09-20 - Categorías: General
¡Hola de nuevo! Hoy les traigo una frikada total. Se trata de un programa para hacer copias de seguridad muy sofisticado y a la vez bastante simple de configurar.
Estoy hablando del FreeFileSync, otro programa de código libre que se publica en SourceForge.net. Donde tenemos que ésta misma semana en que les escribo 13.308 descargas, que son muchas comparando con otros proyectos similares.
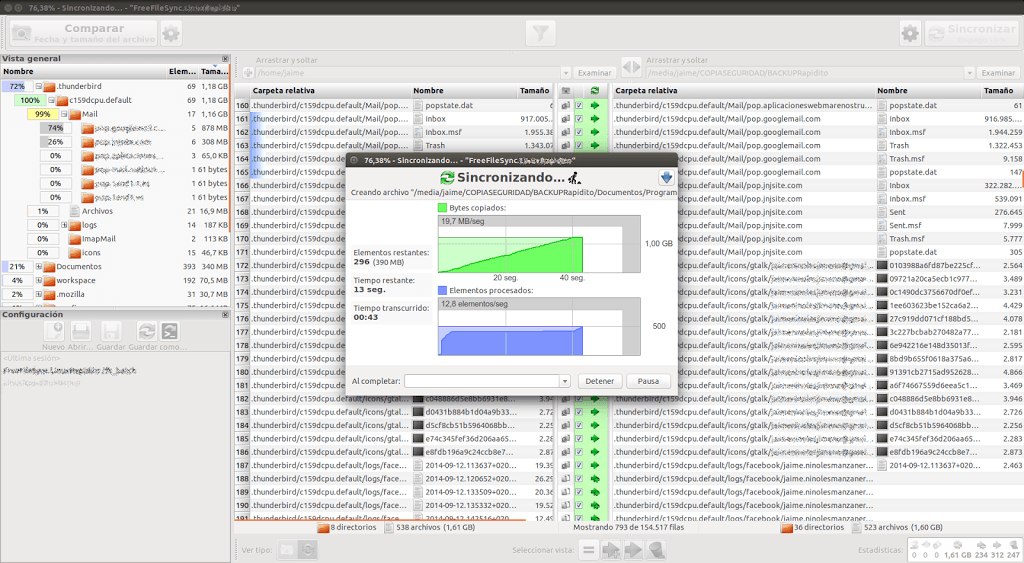
Es un programa muy muy completo. Podemos hacer copias espejo de una carpeta a otra. Podemos hacer sincronización de archivos, donde se comparan dos directorios y sólo se copian los archivos en los que ha habido cambios. Las sincronizaciones se pueden hacer en una dirección o en ambas.
Siempre con todo lujo de detalles en la interfaz gráfica. Veremos qué archivos han cambiado, cuáles se han borrado de qué sitio, qué carpetas tienes más cambios. Tendremos también contadores totales de la cantidad de cambios abajo a la derecha. Permite filtros para sólo copiar ciertos archivos, todos los archivos o para excluir archivos. Y por si no era bastante, cuando se realiza la copia o sincronización se muestra una gráfica de estado en tiempo real como la de la imagen de arriba.
Compatible con Linux, Windows y Mac. Traducido a múltiples idiomas. Se pueden grabar las configuraciones que hagamos para copiar. También se pueden grabar para ejecutar luego como tarea programada del sistema operativo, con lo que, una vez configurado, podemos estar tranquilos. Cada vez que se ejecute tendremos una copia de todos nuestros valiosos archivos.
Lo tenemos en descarga en su página oficial: http://freefilesync.sourceforge.net/
Otra joya de la informática del mundo del código libre. Por supuesto, también es gratis 😉
Un saludo.